auto break case char const continue default dodouble else enum extern float for goto ifint long register return short signed sizeof staticstruct switch typedef union unsigned void volatile while1999年12月16日,ISO推出了C99标准,该标准新增了5个C语言关键字:
define宏定义和const常变量区别: 1.define是宏定义,程序在预处理阶段将用define定义的内容进行了替换。因此程序运行时,常量表中并没有用define定义的常量,系统不为它分配内存。const定义的常量,在程序运行时在常量表中,系统为它分配内存。 2.define定义的常量,预处理时只是直接进行了替换。所以编译时不能进行数据类型检验。const定义的常量,在编译时进行严格的类型检验,可以避免出错。3.define定义表达式时要注意“边缘效应”,例如如下定义: #define N 2+3 //我们预想的N值是5,我们这样使用N,int a = N/2; //我们预想的a的值是2.5,可实际上a的值是3.5原因在于在预处理阶段,编译器将 a = N/2处理成了 a = 2+3/2;这就是宏定义的字符串替换的“边缘效应”因此要如下定义:#define N (2+3)。const定义表达式没有上述问题。const定义的常量叫做常变量原因有二:const定义常量像变量一样检查类型;const可以在任何地方定义常量,编译器对它的处理过程与变量相似,只是分配内存的地方不同。
1
字符串常量, '\0'遇到这个会知道字符串结束了
P6
C语言数据类型的分类方式如下:
基本类型
标准整数类型,以及扩充的整数类型
实数浮点类型,以及复数浮点类型
枚举类型
void类型
派生类型
指针类型
数组类型
结构类型
联合类型
函数类型
1 2
sizeof(a);//return size of a sizeof(int);//return 4单位是字节
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ classSolution{ protectedvoidDFS(TreeNode node, int level, List<List<Integer>> results){ if (level >= results.size()) { LinkedList<Integer> newLevel = new LinkedList<Integer>(); newLevel.add(node.val); results.add(newLevel); } else { if (level % 2 == 0) results.get(level).add(node.val); else results.get(level).add(0, node.val); }
if (node.left != null) DFS(node.left, level + 1, results); if (node.right != null) DFS(node.right, level + 1, results); }
public List<List<Integer>> zigzagLevelOrder(TreeNode root) { if (root == null) { returnnew ArrayList<List<Integer>>(); } List<List<Integer>> results = new ArrayList<List<Integer>>(); DFS(root, 0, results); return results; } }
Approach 1: BFS (Breadth-First Search)
Intuition
Following the description of the problem, the most intuitive solution would be the BFS (Breadth-First Search) approach through which we traverse the tree level-by-level.
The default ordering of BFS within a single level is from left to right. As a result, we should adjust the BFS algorithm a bit to generate the desired zigzag ordering.
One of the keys here is to store the values that are of the same level with the deque (double-ended queue) data structure, where we could add new values on either end of a queue.
So if we want to have the ordering of FIFO (first-in-first-out), we simply append the new elements to the tail of the queue, i.e. the late comers stand last in the queue. While if we want to have the ordering of FILO (first-in-last-out), we insert the new elements to the head of the queue, i.e. the late comers jump the queue.
Algorithm
There are several ways to implement the BFS algorithm.
One way would be that we run a two-level nested loop, with the outer loop iterating each level on the tree, and with the inner loop iterating each node within a single level.
We could also implement BFS with a single loop though. The trick is that we append the nodes to be visited into a queue and we separate nodes of different levels with a sort of delimiter (e.g. an empty node). The delimiter marks the end of a level, as well as the beginning of a new level.
Here we adopt the second approach above. One can start with the normal BFS algorithm, upon which we add a touch of zigzag*order with the help of deque. For each level, we start from an empty deque container to hold all the values of the same level. Depending on the ordering of each level, *i.e. either from-left-to-right or from-right-to-left, we decide at which end of the deque to add the new element:
For the ordering of from-left-to-right (FIFO), we append the new element to the tail\ of the queue, so that the element that comes late would get out late as well. As we can see from the above graph, given an input sequence of [1, 2, 3, 4, 5], with FIFO ordering, we would have an output sequence of [1, 2, 3, 4, 5].
For the ordering of from-right-to-left (FILO), we insert the new element to the head\ of the queue, so that the element that comes late would get out first. With the same input sequence of [1, 2, 3, 4, 5], with FILO ordering, we would obtain an output sequence of [5, 4, 3, 2, 1].
Note: as an alternative approach, one can also implement the normal BFS algorithm first, which would generate the ordering of from-left-to-right for each of the levels. Then, at the end of the algorithm, we can simply reverse\ the ordering of certain levels, following the zigzag steps.
Complexity Analysis
Time Complexity: O(N)O(N), where NN is the number of nodes in the tree.
We visit each node once and only once.
In addition, the insertion operation on either end of the deque takes a constant time, rather than using the array/list data structure where the inserting at the head could take the O(K)O(K) time where KK is the length of the list.
Space Complexity: O(N)O(N) where NN is the number of nodes in the tree.
The main memory consumption of the algorithm is the node_queue that we use for the loop, apart from the array that we use to keep the final output.
As one can see, at any given moment, the node_queue would hold the nodes that are at most across two levels. Therefore, at most, the size of the queue would be no more than 2⋅L2⋅L, assuming LL is the maximum number of nodes that might reside on the same level. Since we have a binary tree, the level that contains the most nodes could occur to consist all the leave nodes in a full binary tree, which is roughly L=N2L=2N. As a result, we have the space complexity of 2⋅N2=N2⋅2N=N in the worst case.
Approach 2: DFS (Depth-First Search)
Intuition
Though not intuitive, we could also obtain the BFS traversal ordering via the DFS (Depth-First Search) traversal in the tree.
The trick is that during the DFS traversal, we maintain the results in a global array that is indexed by the level, i.e. the element array[level] would contain all the nodes that are at the same level. The global array would then be referred and updated at each step of DFS.
Similar with the above modified BFS algorithm, we employ the deque data structure to hold the nodes that are of the same level, and we alternate the insertion direction (i.e. either to the head or to the tail) to generate the desired output ordering.
Algorithm
Here we implement the DFS algorithm via recursion. We define a recursive function called DFS(node, level) which only takes care of the current node which is located at the specified level. Within the function, here are three steps that we would perform:
If this is the first time that we visit any node at the level, i.e. the deque for the level does not exist, then we simply create the deque with the current node value as the initial element.
If the deque for this level exists, then depending on the ordering, we insert the current node value either to the head or to the tail of the queue.
At the end, we recursively call the function for each of its child nodes.
It might go without saying that, one can also implement the DFS traversal via iteration\ rather than recursion, which could be one of the followup questions by an interviewer.
Complexity Analysis
Time Complexity: O(N)O(N), where NN is the number of nodes in the tree.
Same as the previous BFS approach, we visit each node once and only once.
Space Complexity: O(H)O(H), where HH is the height of the tree, i.e. the number of levels in the tree, which would be roughly log2Nlog2N.
Unlike the BFS approach, in the DFS approach, we do not need to maintain the node_queue data structure for the traversal.
However, the function recursion would incur additional memory consumption on the function call stack. As we can see, the size of the call stack for any invocation of DFS(node, level) would be exactly the number of level that the current node resides on. Therefore, the space complexity of our DFS algorithm is O(log2N)O(log2N) which is much better than the BFS approach.
There are two general strategies to traverse a tree:
Depth First Search (DFS)
In this strategy, we adopt the depth as the priority, so that one would start from a root and reach all the way down to a certain leaf, and then back to root to reach another branch.
The DFS strategy can further be distinguished as preorder, inorder, and postorder depending on the relative order among the root node, left node, and right node.
Breadth First Search (BFS)
We scan through the tree level by level, following the order of height, from top to bottom. The nodes on a higher level would be visited before the ones on lower levels.
In the following figure the nodes are enumerated in the order you visit them, please follow 1-2-3-4-5 to compare different strategies.
Here the problem is to implement split-level BFS traversal : [[4, 5], [2, 3], [1]]. That means we could use one of the Node->Left->Right techniques: BFS or DFS Preorder.
We already discussed three different ways to implement iterative BFS traversal with the queue, and compared iterative BFS vs. iterative DFS. Let’s use this article to discuss the two most simple and fast techniques:
Recursive DFS.
Iterative BFS with two queues.
Note, that both approaches are root-to-bottom traversals, and we’re asked to provide bottom-up output. To achieve that, the final result should be reversed.
Approach 1: Recursion: DFS Preorder Traversal
Intuition
The first step is to ensure that the tree is not empty. The second step is to implement the recursive function helper(node, level), which takes the current node and its level as the arguments.
Algorithm for the Recursive Function
Here is its implementation:
Initialize the output list levels. The length of this list determines which level is currently updated. You should compare this level len(levels) with a node level level, to ensure that you add the node on the correct level. If you’re still on the previous level - add the new level by adding a new list into levels.
Append the node value to the last level in levels.
Process recursively child nodes if they are not None: helper(node.left / node.right, level + 1).
Implementation
1 / 16
Complexity Analysis
Time complexity: O(N)O(N) since each node is processed exactly once.
Space complexity: O(N)O(N) to keep the output structure which contains NN node values.
Approach 2: Iteration: BFS Traversal
Algorithm
The recursion above could be rewritten in the iteration form.
Let’s keep each tree level in the queue structure, which typically orders elements in a FIFO (first-in-first-out) manner. In Java one could use ArrayDeque implementation of the Queue interface. In Python using Queue structure would be an overkill since it’s designed for a safe exchange between multiple threads and hence requires locking which leads to a performance downgrade. In Python the queue implementation with a fast atomic append() and popleft() is deque.
Algorithm
Initialize two queues: one for the current level, and one for the next. Add root into nextLevel queue.
While nextLevel queue is not empty:
Initialize the current level currLevel = nextLevel, and empty the next level nextLevel.
Iterate over the current level queue:
Append the node value to the last level in levels.
Add first left and then right child node into nextLevel queue.
Return reversed levels.
Implementation
Complexity Analysis
Time complexity: O(N)O(N) since each node is processed exactly once.
Space complexity: O(N)O(N) to keep the output structure which contains NN node values.
//recursion class Solution { private ArrayList<Integer> helper(TreeNode root, ArrayList<Integer> ans){ if(root==null) return ans; helper(root.left, ans); ans.add(root.val); helper(root.right,ans); return ans; } public int kthSmallest(TreeNode root, int k) { ArrayList<Integer> num= helper(root, new ArrayList<Integer>()); return num.get(k-1); } } //iterative class Solution { public int kthSmallest(TreeNode root, int k) { LinkedList<TreeNode> stack = new LinkedList<TreeNode>();
while (true) { while (root != null) { stack.add(root); root = root.left; } root = stack.removeLast(); if (--k == 0) return root.val; root = root.right; } } }
How to traverse the tree
There are two general strategies to traverse a tree:
Depth First Search (DFS)
In this strategy, we adopt the depth as the priority, so that one would start from a root and reach all the way down to certain leaf, and then back to root to reach another branch.
The DFS strategy can further be distinguished as preorder, inorder, and postorder depending on the relative order among the root node, left node and right node.
Breadth First Search (BFS)
We scan through the tree level by level, following the order of height, from top to bottom. The nodes on higher level would be visited before the ones with lower levels.
On the following figure the nodes are numerated in the order you visit them, please follow 1-2-3-4-5 to compare different strategies.
To solve the problem, one could use the property of BST : inorder traversal of BST is an array sorted in the ascending order.
Approach 1: Recursion
It’s a very straightforward approach with O(N)O(N) time complexity. The idea is to build an inorder traversal of BST which is an array sorted in the ascending order. Now the answer is the k - 1th element of this array.
Complexity Analysis
Time complexity : O(N)O(N) to build a traversal.
Space complexity : O(N)O(N) to keep an inorder traversal.
Approach 2: Iteration
The above recursion could be converted into iteration, with the help of stack. This way one could speed up the solution because there is no need to build the entire inorder traversal, and one could stop after the kth element.
Complexity Analysis
Time complexity : O(H+k)O(H+k), where HH is a tree height. This complexity is defined by the stack, which contains at least H+kH+k elements, since before starting to pop out one has to go down to a leaf. This results in O(logN+k)O(logN+k) for the balanced tree and O(N+k)O(N+k) for completely unbalanced tree with all the nodes in the left subtree.
Space complexity : O(H+k)O(H+k), the same as for time complexity, O(N+k)O(N+k) in the worst case, and O(logN+k)O(logN+k) in the average case.
Follow up
What if the BST is modified (insert/delete operations) often and you need to find the kth smallest frequently? How would you optimize the kthSmallest routine?
Insert and delete in a BST were discussed last week, the time complexity of these operations is O(H)O(H), where HH is a height of binary tree, and H=logNH=logN for the balanced tree.
Hence without any optimisation insert/delete + search of kth element has O(2H+k)O(2H+k) complexity. How to optimise that?
That’s a design question, basically we’re asked to implement a structure which contains a BST inside and optimises the following operations :
Insert
Delete
Find kth smallest
Seems like a database description, isn’t it? Let’s use here the same logic as for LRU cache design, and combine an indexing structure (we could keep BST here) with a double linked list.
Such a structure would provide:
O(H)O(H) time for the insert and delete.
O(k)O(k) for the search of kth smallest.
The overall time complexity for insert/delete + search of kth smallest is O(H+k)O(H+k) instead of O(2H+k)O(2H+k).
Complexity Analysis
Time complexity for insert/delete + search of kth smallest: O(H+k)O(H+k), where HH is a tree height. O(logN+k)O(logN+k) in the average case, O(N+k)O(N+k) in the worst case.
Space complexity : O(N)O(N) to keep the linked list.
classSolution{ int ans=1; publicintdepth(TreeNode node){ if(node==null) return0; int l=depth(node.left); int r=depth(node.right); ans=Math.max(l+r+1,ans); return Math.max(l,r)+1; } publicintdiameterOfBinaryTree(TreeNode root){ depth(root); return ans-1; } }
Approach #1: Depth-First Search [Accepted]
Intuition
Any path can be written as two arrows (in different directions) from some node, where an arrow is a path that starts at some node and only travels down to child nodes.
If we knew the maximum length arrows L, R for each child, then the best path touches L + R + 1 nodes.
Algorithm
Let’s calculate the depth of a node in the usual way: max(depth of node.left, depth of node.right) + 1. While we do, a path “through” this node uses 1 + (depth of node.left) + (depth of node.right) nodes. Let’s search each node and remember the highest number of nodes used in some path. The desired length is 1 minus this number.
Complexity Analysis
Time Complexity: O(N)O(N). We visit every node once.
Space Complexity: O(N)O(N), the size of our implicit call stack during our depth-first search.
663. Equal Tree Partition
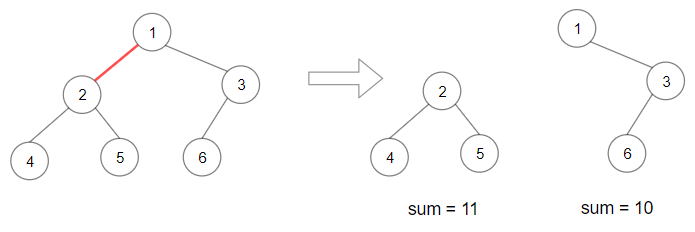
Given a binary tree with n nodes, your task is to check if it’s possible to partition the tree to two trees which have the equal sum of values after removing exactly one edge on the original tree.
After removing some edge from parent to child, (where the child cannot be the original root) the subtree rooted at child must be half the sum of the entire tree.
Let’s record the sum of every subtree. We can do this recursively using depth-first search. After, we should check that half the sum of the entire tree occurs somewhere in our recording (and not from the total of the entire tree.)
Our careful treatment and analysis above prevented errors in the case of these trees:
1 2 3 4 5 6 7
0 / \ -11
0 \ 0
Complexity Analysis
Time Complexity: O(N)O(N) where NN is the number of nodes in the input tree. We traverse every node.
Space Complexity: O(N)O(N), the size of seen and the implicit call stack in our DFS.
class Solution { List<Integer> all=new ArrayList(); private int sum(TreeNode subroot){ if(subroot==null) return 0; int l=sum(subroot.left); int r=sum(subroot.right); int total=l+r+subroot.val; all.add(total); return total; } public int maxProduct(TreeNode root) { long total=sum(root); long ans=0; for(long i:all) ans=Math.max(ans,i*(total-i)); return (int)(ans%1000000007); } }
Approach 1: One-Pass DFS
Intuition
To get started, we’re just going to pretend that integers can be infinitely large.
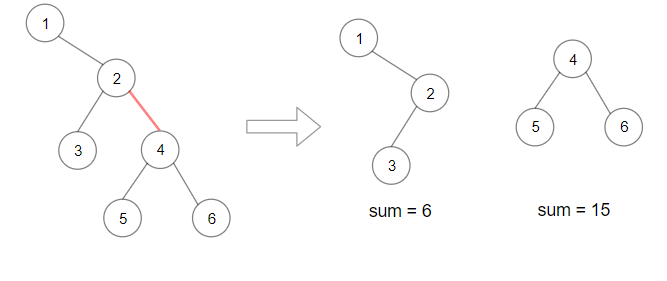
We’ll use the following tree example.
There are n - 1 edges in a tree with n nodes, and so for this question there are n - 1 different possible ways of splitting the tree into a pair of subtrees. Here are 4 out of the 10 possible ways.
Of these 4 possible ways, the best is the third one, which has a product of 651.
To make it easier to discuss the solution, we’ll name each of the subtrees in a pair.
One of the new subtrees is rooted at the node below the removed edge. We’ll call it Subtree 1.
The other is rooted at the root node of the original tree, and is missing the subtree below the removed edge. We’ll call it Subtree 2.
Remember that we’re required to find the pair of subtrees that have the maximum product. This is done by calculating the sum of each subtree and then multiplying them together. The sum of a subtree is the sum of all the nodes in it.
Calculating the sum of Subtree 1 can be done using the following recursive tree algorithm. The root of Subtree 1 is passed into the function.
This algorithm calculates the sum of a subtree by calculating the sum of its left subtree, sum of its right subtree, and then adding these to the root value. The sum of the left and right subtrees is done in the same way by the recursion.
If you’re confused by this recursive summing algorithm, it might help you to read this article on solving tree problems with recursive (top down) algorithms.
We still need a way to calculate the sum of Subtree 2. Recall that Subtree 2 is the tree we get by removing Subtree 1. The only way we could directly use the above summing algorithm to calculate the sum of Subtree 2 is to actually remove the edge above Subtree 1 first. Otherwise, Subtree 1 would be automatically traversed too.
A simpler way is to recognise that Sum(Subtree 2) = Sum(Entire Tree) - Sum(Sub Tree 1).
Another benefit of this approach is that we only need to calculate Sum(Entire Tree) once. Then, for each Sum(Subtree 1) we calculate, we can immediately calculate Sum(Subtree 2) as an O(1)O(1) operation.
Recall how the summing algorithm above worked. The recursive function is called once for every node in the tree (i.e. subtree rooted at that node), and returns the sum of that subtree.
Therefore we can simply gather up all the possible Subtree 1 sums with a list as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13
subtree_1_sums = [] # All Subtree 1 sums will go here.
deftree_sum(subroot): if subroot isNone: return0 left_sum = tree_sum(subroot.left) right_sum = tree_sum(subroot.right) subtree_sum = left_sum + right_sum + subroot.val subtree_1_sums.append(subtree_sum) # Add this subtree sum to the list. return subtree_sum
total_sum = tree_sum(root) # Call with the root of the entire tree. print(subtree_1_sums) # This is all the subree sums.
Now that we have a list of the sums for all possible Subtree 1‘s, we can calculate what the corresponding Subtree 2 would be for each of them, and then calculate the product, keeping track of the best seen so far.
1 2 3 4 5 6 7 8 9 10 11 12
# Call the function. subtree_1_sums = [] # Populate by function call. total_sum = tree_sum(root)
best_product = 0 # Find the best product. for subtree_1_sum in subtree_1_sums: subtree_2_sum = total_sum - subtree_1_sum product = subtree_1_sum * subtree_2_sum best_product = max(best_product, product)
print(best_product)
The question also says we need to take the answer modulo 10 ^ 9 + 7. Expanded out, this number is 1,000,000,007. So when we return the product, we’ll do:
1
best_product % 1000000007
Only take the final product modulo 10 ^ 9 + 7. Otherwise, you might not be correctly comparing the products.
Up until now, we’ve assumed that integers can be of an infinite size. This is a safe assumption for Python, but not for Java. For Java (and other languages that use a 32-bit integer by default), we’ll need to think carefully about where integer overflows could occur.
The problem statement states that there can be up to 50000 nodes, each with a value of up to 10000. Therefore, the maximum possible subtree sum would be 50,000 * 10,000 = 500,000,000. This is well below the size of a 32-bit integer (2,147,483,647). Therefore, it is impossible for an integer overflow to occur during the summing phase with these constraints.
However, multiplying the subtrees could be a problem. For example, if we had subtrees of 100,000,000 and 400,000,000, then we’d get a total product of 400,000,000,000,000,000 which is definitely larger than a 32-bit integer, and therefore and overflow would occur!
The easiest solution is to instead use 64-bit integers. In Java, this is the long primitive type. The largest possible product would be 250,000,000 * 250,000,000 = 62,500,000,000,000,000, which is below the maximum a 64-bit integer can hold.
In Approach #3, we discuss other ways of solving the problem if you only had access to 32-bit integers.
Algorithm
Complexity Analysis
nn is the number of nodes in the tree.
Time Complexity : O(n)O(n).
The recursive function visits each of the nn nodes in the tree exactly once, performing an O(1)O(1) recursive operation on each. This gives a total of O(n)O(n)
There are n−1n−1 numbers in the list. Each of these is processed with an O(1)O(1) operation, giving a total of O(n)O(n) time for this phase too.
In total, we have O(n)O(n).
Space Complexity O(n)O(n).
There are two places that extra space is used.
Firstly, the recursion is putting frames on the stack. The maximum number of frames at any one time is the maximum depth of the tree. For a balanced tree, this is around O(log n)O(logn), and in the worst case (a long skinny tree) it is O(n)O(n).
Secondly, the list takes up space. It contains n−1n−1 numbers at the end, so it too is O(n)O(n).
In both the average case and worst case, we have a total of O(n)O(n) space used by this approach.
Something you might have realised is that the subtree pair that leads to the largest product is the pair with the smallest difference between them. Interestingly, this fact doesn’t help us much with optimizing the algorithm. This is because subtree sums are notobtained in sorted order, and so any attempt to sort them (and thus find the nearest to middle directly) will cost at least O(n log n)O(nlogn) to do. With the overall algorithm, even with the linear search, only being O(n)O(n), this is strictly worse. The only situation this insight becomes useful is if you have to solve the problem using only 32-bit integers. The reason for this is discussed in Approach #3.
Approach 2: Two-Pass DFS
Intuition
Instead of putting the Subtree 1 sums into a separate list, we can do 2 separate tree summing traversals.
Calculate the sum of the entire tree.
Check the product we’d get for each subtree.
Calculating the total sum is done in the same way as before.
Finding the maximum product is similar, except requires a variable outside of the function to keep track of the maximum product seen so far.
1 2 3 4 5 6 7 8 9 10 11 12 13
defmaximum_product(subroot, total): best = 0 defrecursive_helper(subroot): nonlocal best if subroot isNone: return0 left_sum = recursive_helper(subroot.left) right_sum = recursive_helper(subroot.right) total_sum = left_sum + right_sum + subroot.val product = total_sum * (tree_total_sum - total_sum) best = max(best, product) return total_sum recursive_helper(subroot) return best
Algorithm
It is possible to combine the 2 recursive functions into a single one that is called twice, however the side effects of the functions (changing of class variables) hurt code readability and can be confusing. For this reason, the code below uses 2 separate functions.
Complexity Analysis
nn is the number of nodes in the tree.
Time Complexity : O(n)O(n).
Each recursive function visits each of the nn nodes in the tree exactly once, performing an O(1)O(1) recursive operation on each. This gives a total of O(n)O(n).
Space Complexity O(n)O(n).
The recursion is putting frames on the stack. The maximum number of frames at any one time is the maximum depth of the tree. For a balanced tree, this is around O(log n)O(logn), and in the worst case (a long skinny tree) it is O(n)O(n).
Because we use worst case for complexity analysis, we say this algorithm uses O(n)O(n) space. However, it’s worth noting that as long as the tree is fairly balanced, the space usage will be a lot nearer to O(log n)O(logn).
Approach 3: Advanced Strategies for Dealing with 32-Bit Integers
Intuition
This is an advanced bonus section that discusses ways of solving the problem using only 32-bit integers. It’s not essential for an interview, although could be useful depending on your choice of programming language. Some of the ideas might also help with potential follow up questions. This section assumes prior experience with introductory modular arithmetic.
We’ll additionally assume that the 32-bit integer we’re working with is signed, so has a maximum value of 2,147,483,647.
What if your chosen programming language only supported 32-bit integers, and you had no access to a Big Integer library? Could we still solve this problem? What are the problems we’d need to address?
The solutions above relied on being able to multiply 2 numbers of up to 30 (signed) bits each without overflow. Because the number of bits in the product add, we would expect the product to require ~60 bits to represent. Using a 64-bit integer was therefore enough. Additionally, with a modulus of 1,000,000,007, the final product, after taken to the modulus, will always fit within a 32-bit integer.
However, we’re now assuming that we only have 32-bit integers. When working with 32-bit integers, we must always keep the total below 2,147,483,647, even during intermediate calculations. Therefore, we’ll need a way of doing the math within this restriction. One way to do the multiplication safely is to write an algorithm using the same underlying idea as modular exponentiation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
privateintmodularMultiplication(int a, int b, int m){ int product = 0; int currentSum = a; while (b > 0) { int bit = b % 2; b >>= 1; if (bit == 1) { product += currentSum; product %= m; } currentSum <<= 1; currentSum %= m; } return product; }
There is one possible pitfall with this though. We are supposed to return the calculation for the largest product, determined before the modulus is taken.
So if we were to compare them before taking the modulus, product 1 would be larger, which is correct. But if we compared them after, then product 2 is larger, which is incorrect.
Therefore, we need a way to determine which product will be the biggest, without actually calculating them. Then once we know which is biggest, we can use our method for calculating a product modulo 1,000,000,007 without going over 2,147,483,647.
The trick is to realise that Sum(Subtree 1) + Sum(Subtree 2) is constant, but Sum(Subtree 1) * Sum(Subtree 2) increases as Sum(Subtree 1) - Sum(Subtree 2) gets nearer to 0, i.e. as the sum of the subtrees is more balanced. A good way of visualising this is to imagine you have X meters of fence and need to make a rectangular enclosure for some sheep. You want to maximise the area. It turns out that the optimal solution is to make a square. The nearer to a square the enclosure is, the nearer to the optimal area it will be. For example, where H + W = 11, the best (integer) solution is 5 x 6 = 30.
A simple way to do this in code is to loop over the list of all the sums and find the (sum, total - sum) pair that has the minimal difference. This approach ensures we do not need to use floating point numbers.
Algorithm
We’ll use Approach #1 as a basis for the code, as it’s simpler and easier to understand. The same ideas can be used in Approach #2 though.
Complexity Analysis
nn is the number of nodes in the tree.
Time Complexity : O(n)O(n).
Same as above approaches.
Space Complexity : O(n)O(n).
Same as above approaches.
The modularMultiplication function has a time complexity of O(log b)O(logb) because the loop removes one bit from bb each iteration, until there are none left. This doesn’t bring up the total time complexity to O(n log b)O(nlogb) though, because bb has a fixed upper limit of 32, and is therefore treated as a constant.
classSolution{ publicintrob(int[] nums){ int premax=0; int curmax=0; for(int x:nums){ int tmp=curmax; curmax=Math.max(x+premax,curmax); premax=tmp; } return curmax; } }
Algorithm
It could be overwhelming thinking of all possibilities on which houses to rob.
A natural way to approach this problem is to work on the simplest case first.
Let us denote that:
f(k) = Largest amount that you can rob from the first k houses. Ai = Amount of money at the ith house.
Let us look at the case n = 1, clearly f(1) = A1.
Now, let us look at n = 2, which f(2) = max(A1, A2).
For n = 3, you have basically the following two options:
Rob the third house, and add its amount to the first house’s amount.
Do not rob the third house, and stick with the maximum amount of the first two houses.
Clearly, you would want to choose the larger of the two options at each step.
Therefore, we could summarize the formula as following:
f(k) = max(f(k – 2) + Ak, f(k – 1))
We choose the base case as f(–1) = f(0) = 0, which will greatly simplify our code as you can see.
The answer will be calculated as f(n). We could use an array to store and calculate the result, but since at each step you only need the previous two maximum values, two variables are suffice.
1 2 3 4 5 6 7 8 9 10
publicintrob(int[] num){ int prevMax = 0; int currMax = 0; for (int x : num) { int temp = currMax; currMax = Math.max(prevMax + x, currMax); prevMax = temp; } return currMax; }
Complexity analysis
Time complexity : O(n)O(n). Assume that nn is the number of houses, the time complexity is O(n)O(n).
classSolution{ publicintrob(int[] nums){ int l=nums.length; if(l<=0)return0; if(l==1)return nums[0]; if(l==2)return Math.max(nums[0],nums[1]); return Math.max(rob0(nums),rob1(nums)); } publicintrob0(int[] nums){//0~length-2 int premax=0; int curmax=0; int l=nums.length; int[] arr1=newint[l-1]; System.arraycopy(nums,0,arr1,0,l-1);//copy array for(int x:arr1){ int tmp=curmax; curmax=Math.max(x+premax,curmax); premax=tmp; } return curmax; } publicintrob1(int[] nums){//0~length-1 int premax=0; int curmax=0; int l=nums.length; int[] arr2=newint[l-1]; System.arraycopy(nums,1,arr2,0,l-1); for(int x:arr2){ int tmp=curmax; curmax=Math.max(x+premax,curmax); premax=tmp; } return curmax; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution{ publicintrob(int[] nums){ if (nums.length == 1) return nums[0]; return Math.max(rob(nums, 0, nums.length - 2), rob(nums, 1, nums.length - 1)); } privateintrob(int[] num, int lo, int hi){ int include = 0, exclude = 0; for (int j = lo; j <= hi; j++) { int i = include, e = exclude; include = e + num[j]; exclude = Math.max(e, i); } return Math.max(include, exclude); } }
Since this question is a follow-up to House Robber, we can assume we already have a way to solve the simpler question, i.e. given a 1 row of house, we know how to rob them. So we already have such a helper function. We modify it a bit to rob a given range of houses.
1 2 3 4 5 6 7 8 9
private int rob(int[] num, int lo, int hi) { int include = 0, exclude = 0; for (int j = lo; j <= hi; j++) { int i = include, e = exclude; include = e + num[j]; exclude = Math.max(e, i); } return Math.max(include, exclude); }
Now the question is how to rob a circular row of houses. It is a bit complicated to solve like the simpler question. It is because in the simpler question whether to rob num[lo] is entirely our choice. But, it is now constrained by whether num[hi] is robbed.
However, since we already have a nice solution to the simpler problem. We do not want to throw it away. Then, it becomes how can we reduce this problem to the simpler one. Actually, extending from the logic that if house i is not robbed, then you are free to choose whether to rob house i + 1, you can break the circle by assuming a house is not robbed.
For example, 1 -> 2 -> 3 -> 1 becomes 2 -> 3 if 1 is not robbed.
Since every house is either robbed or not robbed and at least half of the houses are not robbed, the solution is simply the larger of two cases with consecutive houses, i.e. house i not robbed, break the circle, solve it, or house i + 1 not robbed. Hence, the following solution. I chose i = n and i + 1 = 0 for simpler coding. But, you can choose whichever two consecutive ones.
1 2 3 4
public int rob(int[] nums) { if (nums.length == 1) return nums[0]; return Math.max(rob(nums, 0, nums.length - 2), rob(nums, 1, nums.length - 1)); }
The simplest approach consists of trying to find out every possible square of 1’s that can be formed from within the matrix. The question now is – how to go for it?
We use a variable to contain the size of the largest square found so far and another variable to store the size of the current, both initialized to 0. Starting from the left uppermost point in the matrix, we search for a 1. No operation needs to be done for a 0. Whenever a 1 is found, we try to find out the largest square that can be formed including that 1. For this, we move diagonally (right and downwards), i.e. we increment the row index and column index temporarily and then check whether all the elements of that row and column are 1 or not. If all the elements happen to be 1, we move diagonally further as previously. If even one element turns out to be 0, we stop this diagonal movement and update the size of the largest square. Now we, continue the traversal of the matrix from the element next to the initial 1 found, till all the elements of the matrix have been traversed.
We also remember the size of the largest square found so far. In this way, we traverse the original matrix once and find out the required maximum size. This gives the side length of the square (say maxsqlenmaxsqle**n). The required result is the area maxsqlen2m*axsqlen*2.
To understand how this solution works, see the figure below.
An entry 2 at (1,3)(1,3) implies that we have a square of side 2 up to that index in the original matrix. Similarly, a 2 at (1,2)(1,2) and (2,2)(2,2)implies that a square of side 2 exists up to that index in the original matrix. Now to make a square of side 3, only a single entry of 1 is pending at (2,3)(2,3). So, we enter a 3 corresponding to that position in the dp array.
Now consider the case for the index (3,4)(3,4). Here, the entries at index (3,3)(3,3) and (2,3)(2,3) imply that a square of side 3 is possible up to their indices. But, the entry 1 at index (2,4)(2,4) indicates that a square of side 1 only can be formed up to its index. Therefore, while making an entry at the index (3,4)(3,4), this element obstructs the formation of a square having a side larger than 2. Thus, the maximum sized square that can be formed up to this index is of size 2×22×2.
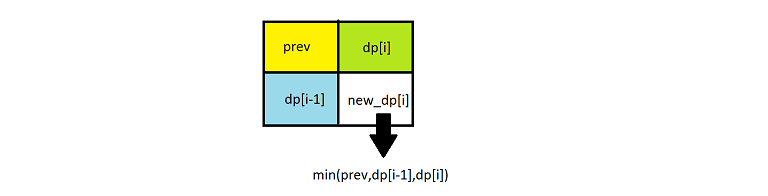
In the previous approach for calculating dp of ithith row we are using only the previous element and the (i−1)(i−1)t**h row. Therefore, we don’t need 2D dp matrix as 1D dp array will be sufficient for this.
Initially the dp array contains all 0’s. As we scan the elements of the original matrix across a row, we keep on updating the dp array as per the equation dp[j]=min(dp[j−1],dp[j],prev)d**p[j]=min(d**p[j−1],d**p[j],pre**v), where prev refers to the old dp[j−1]d**p[j−1]. For every row, we repeat the same process and update in the same dp array.
Approach 1: Dynamic Programming with State Machine
Intuition
First of all, let us take a different perspective to look at the problem, unlike the other algorithmic problems.
Here, we will treat the problem as a game, and the trader as an agent in the game. The agent can take actions that lead to gain or lose of game points (i.e. profits). And the goal of the game for the agent is to gain the maximal points.
In addition, we will introduce a tool called state machine, which is a mathematical model of computation. Later one will see how the state machine coupled with the dynamic programming technique can help us solve the problem easily.
In the following sections, we will first define a state machine that is used to model the behaviors and states of the game agent.
Then, we will demonstrate how to apply the state machine to solve the problem.
Definition
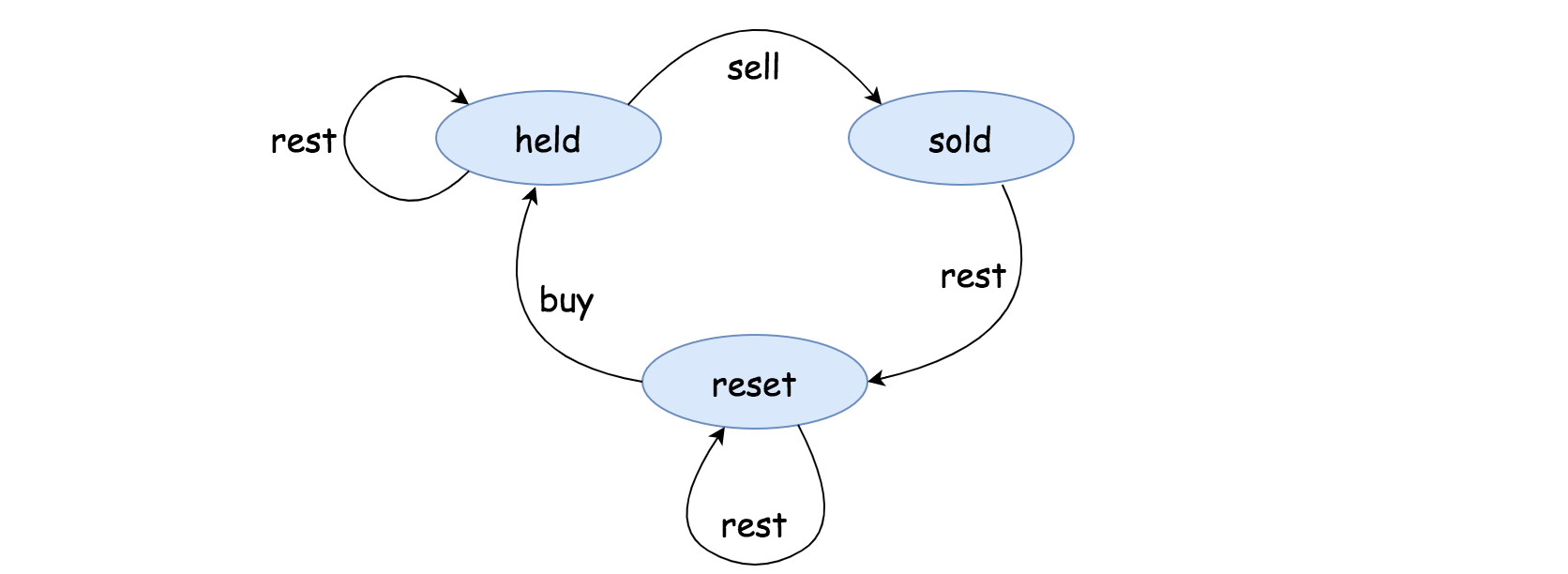
Let us define a state machine\ to model our agent. The state machine consists of three states, which we define as follows:
state held: in this state, the agent holds a stock that it bought at some point before.
state sold: in this state, the agent has just sold a stock right before entering this state. And the agent holds no stock at hand.
state reset: first of all, one can consider this state as the starting point, where the agent holds no stock and did not sell a stock before. More importantly, it is also the transient state before the held and sold. Due to the cooldown\ rule, after the sold state, the agent can not immediately acquire any stock, but is forced into the reset state. One can consider this state as a “reset” button for the cycles of buy and sell transactions.
At any moment, the agent can only be in one\ state. The agent would transition to another state by performing some actions, namely:
action sell: the agent sells a stock at the current moment. After this action, the agent would transition to the sold state.
action buy: the agent acquires a stock at the current moment. After this action, the agent would transition to the heldstate.
action rest: this is the action that the agent does no transaction, neither buy or sell. For instance, while holding a stock at the held state, the agent might simply do nothing, and at the next moment the agent would remain in the held state.
Now, we can assemble the above states and actions into a state machine, which we show in the following graph where each node represents a state, and each edge represents a transition between two states. On top of each edge, we indicate the action that triggers the transition.
Notice that, in all states except the sold state, by doing nothing, we would remain in the same state, which is why there is a self-looped transition on these states.
Deduction
Now, one might wonder how exactly the state machine that we defined can help to solve the problem.
As we mentioned before, we model the problem as a game\, and the trader as an agent\ in the game. And this is where our state machine comes into the picture. The behaviors and the states of the game agent can be modeled by our state machine.
Given a list stock prices (i.e.price[0...n]), our agent would walk through each price point one by one. At each point, the agent would be in one of three states (i.e.held, sold and reset) that we defined before. And at each point, the agent would take one of the three actions (i.e.buy, sell and rest), which then would lead to the next state at the next price point.
Now if we chain up each state at each price point, it would form a graph\ where each path\ that starts from the initial price point and ends at the last price point represents a combination of transactions that the agent could perform through out the game.
The above graph shows all possible paths that our game agent agent walks through the list, which corresponds to all possible combinations of transactions that the trader can perform with the given price sequence.
In order to solve the problem, the goal is to find such a path in the above graph that maximizes the profits.
In each node of graph, we also indicate the maximal profits that the agent has gained so far in each state of each step. And we highlight the path that generates the maximal profits. Don’t worry about them for the moment. We will explain in detail how to calculate in the next section.
Algorithm
In order to implement the above state machine, we could define three arrays (i.e.held[i], sold[i] and reset[i]) which correspond to the three states that we defined before.
Each element in each array represents the maximal profits that we could gain at the specific price point i with the specific state. For instance, the element sold[2] represents the maximal profits we gain if we sell the stock at the price point price[2].
According to the state machine we defined before, we can then deduce the formulas to calculate the values for the state arrays, as follows:
sold[i]sold[i]: the previous state of sold can only be held. Therefore, the maximal profits of this state is the maximal profits of the previous state plus the revenue by selling the stock at the current price.
held[i]held[i]: the previous state of held could also be held, i.e. one does no transaction. Or its previous state could be reset, from which state, one can acquire a stock at the current price point.
reset[i]reset[i]: the previous state of reset could either be reset or sold. Both transitions do not involve any transaction with the stock.
Finally, the maximal profits that we can gain from this game would be max(sold[n],reset[n])max(sold[n],reset[n]), i.e. at the last price point, either we sell the stock or we simply do no transaction, to have the maximal profits. It makes no sense to acquire the stock at the last price point, which only leads to the reduction of profits.
In particular, as a base case, the game should be kicked off from the state reset, since initially we don’t hold any stock and we don’t have any stock to sell neither. Therefore, we assign the initial values of sold[-1] and held[-1] to be Integer.MIN_VALUE, which are intended to render the paths that start from these two states impossible.
As one might notice in the above formulas, in order to calculate the value for each array, we reuse the intermediate values, and this is where the paradigm of dynamic programming comes into play.
More specifically, we only need the intermediate values at exactly one step before the current step. As a result, rather than keeping all the values in the three arrays, we could use a sliding window\ of size 1 to calculate the value for max(sold[n],reset[n])max(sold[n],reset[n]).
In the following animation, we demonstrate the process on how the three arrays are calculated step by step.
1 / 7
As a byproduct\ of this algorithm, not only would we obtain the maximal profits at the end, but also we could recover each action that we should perform along the path, although this is not required by the problem.
In the above graph, by starting from the final state, and walking backward following the path, we could obtain a sequence of actions that leads to the maximal profits at the end, i.e. [buy, sell, cooldown, buy, sell].
Complexity Analysis
Time Complexity: O(N)O(N) where NN is the length of the input price list.
We have one loop over the input list, and the operation within one iteration takes constant time.
Space Complexity: O(1)O(1), constant memory is used regardless the size of the input.
Approach 2: Yet-Another Dynamic Programming
Intuition
Most of the times, there are more than one approaches to decompose the problem, so that we could apply the technique of dynamic programming.
Here we would like to propose a different perspective on how to model the problem purely with mathematical formulas.
Again, this would be a journey loaded with mathematical notations, which might be complicated, but it showcases how the mathematics could help one with the dynamic programming (pun intended).
Definition
For a sequence of prices, denoted as price[0,1,…,n]price[0,1,…,n], let us first define our target function called MP(i)MP(i). The function MP(i)MP(i)gives the maximal profits that we can gain for the price subsequence starting from the index ii, i.e. price[i,i+1,…,n]price[i,i+1,…,n].
Given the definition of the MP(i)MP(i) function, one can see that when i=0i=0 the output of the function, i.e. MP(0)MP(0), is exactly the result that we need to solve the problem, which is the maximal profits that one can gain for the price subsequence of price[0,1,…,n]price[0,1,…,n].
Suppose that we know all the values for MP(i)MP(i) onwards until MP(n)MP(n), i.e. we know the maximal profits that we can gain for any subsequence of price[k…n]k∈[i,n]price[k…n]k∈[i,n].
Now, let us add a new price point price[i−1]price[i−1] into the subsequence price[i…n]price[i…n], all we need to do is to deduce the value for the unknown MP(i−1)MP(i−1).
Up to this point, we have just modeled the problem with our target function MP(i)MP(i), along with a series of definitions. The problem now is boiled down to deducing the formula for MP(i−1)MP(i−1).
In the following section, we will demonstrate how to deduce the formula for MP(i−1)MP(i−1).
Deduction
With the newly-added price point price[i−1]price[i−1], we need to consider all possible transactions that we can do to the stock at this price point, which can be broken down into two cases:
Case 1): we buy this stock with price[i−1]price[i−1] and then sell it at some point in the following price sequence of price[i…n]price[i…n]. Note that, once we sell the stock at a certain point, we need to cool down for a day, then we can reengage with further transactions. Suppose that we sell the stock right after we bought it, at the next price point price[i]price[i], the maximal profits we would gain from this choice would be the profit of this transaction (i.e. price[i]−price[i−1]price[i]−price[i−1]) plus the maximal profits from the rest of the price sequence, as we show in the following:
In addition, we need to enumerate all possible points to sell this stock, and take the maximum among them. The maximal profits that we could gain from this case can be represented by the following:
Case 2): we simply do nothing with this stock. Then the maximal profits that we can gain from this case would be MP(i)MP(i), which are also the maximal profits that we can gain from the rest of the price sequence.
C2=MP(i)C2=MP(i)
By combining the above two cases, i.e. selecting the max value among them, we can obtain the value for MP(i−1)MP(i−1), as follows:
By the way, the base case for our recursive function MP(i)MP(i) would be MP(n)MP(n) which is the maximal profits that we can gain from the sequence with a single price point price[n]price[n]. And the best thing we should do with a single price point is to do no transaction, hence we would neither lose money nor gain any profit, i.e. MP(n)=0MP(n)=0.
The above formulas do model the problem soundly. In addition, one should be able to translate them directly into code.
Algorithm
With the final formula we derived for our target function MP(i)MP(i), we can now go ahead and translate it into any programming language.
Since the formula deals with subsequences of price that start from the last price point, we then could do an iteration over the price list in the reversed order.
We define an array MP[i] to hold the values for our target function MP(i)MP(i). We initialize the array with zeros, which correspond to the base case where the minimal profits that we can gain is zero. Note that, here we did a trick to pad the array with two additional elements, which is intended to simplify the branching conditions, as one will see later.
To calculate the value for each element MP[i], we need to look into two cases as we discussed in the previous section, namely:
Case 1). we buy the stock at the price point price[i], then we sell it at a later point. As one might notice, the initial padding on the MP[i] array saves us from getting out of boundary in the array.
Case 2). we do no transaction with the stock at the price point price[i].
At the end of each iteration, we then pick the largest value from the above two cases as the final value for MP[i].
At the end of the loop, the MP[i] array will be populated. We then return the value of MP[0], which is the desired solution for the problem.
Complexity Analysis
Time Complexity: O(N2)O(N2) where NN is the length of the price list.
As one can see, we have nested loops over the price list. The number of iterations in the outer loop is NN. The number of iterations in the inner loop varies from 11 to NN. Therefore, the total number of iterations that we perform is ∑i=1Ni=N⋅(N+1)2∑i=1N**i=2N⋅(N+1).
As a result, the overall time complexity of the algorithm is O(N2)O(N2).
Space Complexity: O(N)O(N) where NN is the length of the price list.
We allocated an array to hold all the values for our target function MP(i)MP(i).
我们这一步针对重复子问题进行优化,我们在做斐波那契数列时,使用的优化方案是记忆化,但是之前的问题都是使用数组解决的,把每次计算的结果都存起来,下次如果再来计算,就从缓存中取,不再计算了,这样就保证每个数字只计算一次。 由于二叉树不适合拿数组当缓存,我们这次使用哈希表来存储结果,TreeNode 当做 key,能偷的钱当做 value
解法一加上记忆化优化后代码如下:
Java public int rob(TreeNode root) { HashMap<TreeNode, Integer> memo = new HashMap<>(); return robInternal(root, memo); }
public int robInternal(TreeNode root, HashMap<TreeNode, Integer> memo) { if (root == null) return 0; if (memo.containsKey(root)) return memo.get(root); int money = root.val;
if (root.left != null) {
money += (robInternal(root.left.left, memo) + robInternal(root.left.right, memo));
}
if (root.right != null) {
money += (robInternal(root.right.left, memo) + robInternal(root.right.right, memo));
}
int result = Math.max(money, robInternal(root.left, memo) + robInternal(root.right, memo));
memo.put(root, result);
return result;
classSolution{ publicintnumberOfArithmeticSlices(int[] A){ int result=0; int l=A.length; int[] dp=newint[l]; for(int i=2;i<l;i++){ if(A[i]-A[i-1]==A[i-1]-A[i-2]){ dp[i]=1+dp[i-1]; result+=dp[i]; } } return result; } }
Approach #1 Brute Force [Accepted]
The most naive solution is to consider every pair of elements(with atleast 1 element between them), so that the range of elements lying between these two elements acts as a slice. Then, we can iterate over every such slice(range) to check if all the consecutive elements within this range have the same difference. For every such range found, we can increment the countcount that is used to keep a track of the required result.
Complexity Analysis
Time complexity : O(n3)O(n3). We iterate over the range formed by every pair of elements. Here, nn refers to the number of elements in the given array AA.
Space complexity : O(1)O(1). Constant extra space is used.
Approach #2 Better Brute Force [Accepted]
Algorithm
In the last approach, we considered every possible range and then iterated over the range to check if the difference between every consercutive element in this range is the same. We can optimize this approach to some extent, by making a small observation.
We can see, that if we are currently considering the range bound by the elements, let’s say, A[s]As and A[e]Ae, we have checked the consecutive elements in this range to have the same difference. Now, when we move on to the next range between the indices ss and e+1e+1, we again perform a check on all the elements in the range s:es:e, along with one additional pair A[e+1]A[e+1]and A[e]A[e]. We can remove this redundant check in the range s:es:e and just check the last pair to have the same difference as the one used for the previous range(same ss, incremented ee).
Note that if the last range didn’t constitute an arithmetic slice, the same elements will be a part of the updated range as well. Thus, we can omit the rest of the ranges consisting of the same starting index. The rest of the process remains the same as in the last approach.
Complexity Analysis
Time complexity : O(n2)O(n2). Two for loops are used.
Space complexity : O(1)O(1). Constant extra space is used.
Approach #3 Using Recursion [Accepted]
Algorithm
By making use of the observation discussed in the last approach, we know, that if a range of elements between the indices (i,j)(i,j)constitute an Arithmetic Slice, and another element A[j+1]A[j+1] is included such that A[j+1]A[j+1] and A[j]A[j] have the same difference as that of the previous common difference, the ranges between (i,j+1)(i,j+1) will constitutes an arithmetic slice. Further, if the original range (i,j)(i,j) doesn’t form an arithmetic slice, adding new elements to this range won’t do us any good. Thus, no more arithmetic slices can be obtained by adding new elements to it.
By making use of this observation, we can develop a recursive solution for the given problem as well. Assume that a sumsum variable is used to store the total number of arithmetic slices in the given array AA. We make use of a recursive function slices(A,i)which returns the number of Arithmetic Slices in the range (k,i)(k,i), but which are not a part of any range (k,j)(k,j) such that j<ij<i. It also updates sumsum with the number of arithmetic slices(total) in the current range. Thus, kk refers to the minimum index such that the range (k,i)(k,i) constitutes a valid arithmetic slice.
Now, suppose we know the number of arithmetic slices in the range (0,i−1)(0,i−1) constituted by the elements [a0,a1,a2,…a(i−1)][a0,a1,a2,…a(i−1)], to be say xx. If this range itself is an arithmetic slice, all the consecutive elements have the same difference(equal to say, a(i−1)−a(i−2)a(i−1)−a(i−2)). Now, adding a new element aia**i to it to extend the range to (0,i)(0,i) will constitute an arithmetic slice only if this new element satisfies ai−a(i−1)=a(i−1)−a(i−2)a*i−*a(i−1)=a(i−1)−a(i−2). Thus, now, the addition of this new element, will lead to an addition of apa**p number of arithmetic slices to the ones obtained in the range (0,i−1)(0,i−1). The new arithmetic slices will be the ones constituting the ranges (0,i),(1,i),…(i−2,i)(0,i),(1,i),…(i−2,i), which are a total of x+1x+1 additional arithmetic slices. This is because, apart from the range (0,i)(0,i) the rest of the ranges (1,i),(2,i),…(i−2,i)(1,i),(2,i),…(i−2,i) can be mapped to (0,i−1),(1,i−1),…(i−3,i−1)(0,i−1),(1,i−1),…(i−3,i−1), with count equal to xx.
Thus, in every call to slices, if the ithith element has the same common difference with the last element as the previous common difference, we can find the number of new arithmetic slices added by the use of this element, apa**p and also update the sumsum to include this apa**p into it, apart from the count obtained by the smaller ranges. But, if the new element doesn’t have the same common difference, extra arithmetic slices can’t be contributed by it and hence, no addition is done to sumsum for the current element. But, of course sumsum will be updated as per the count obtained from the smaller ranges.
Complexity Analysis
Time complexity : O(n)O(n). The recursive function is called at most n−2n−2 times.
Space complexity : O(n)O(n). The depth of the recursion tree goes upto n−2n−2.
Approach #5 Dynamic Programming [Accepted]:
Algorithm
In the last approach, we start with the full range (0,n−1)(0,n−1), where nn is the number of elements in the given AA array. We can observe that the result for the range (0,i)(0,i) only depends on the elements in the range (0,i)(0,i) and not on any element beyond this range. Thus, we can make use of Dynamic Programming to solve the given problem.
We can make use of a 1-D dpd**p with number of elements equal to nn. dp[i]d**p[i] is used to store the number of arithmetic slices possible in the range (k,i)(k,i) and not in any range (k,j)(k,j) such that j<ij<i. Again, kk refers to the minimum index possible such that (k,j)(k,j)constitutes a valid Arithmetic Slice.
Instead of going in the reverse order as in the recursive approach, we can start filling the dpd**p in a forward manner. The intuition remains the same as in the last approach. For the ithith element being considered, we check if this element satsfies the common difference criteria with the previous element. If so, we know the number of new arithmetic slices added will be 1+dp[i−1]1+d**p[i−1] as discussed in the last approach. The sumsum is also updated by the same count to reflect the new arithmetic slices added.
The following animation illustrates the dpd**p filling process.
1 / 9
Complexity Analysis
Time complexity : O(n)O(n). We traverse over the given AA array with nn elements once only.
Space complexity : O(n)O(n). 1-D dpd**p of size nn is used.
Approach #5 Constant Space Dynamic Programming [Accepted]:
Algorithm
In the last approach, we can observe that we only require the element dp[i−1]d**p[i−1] to determine the value to be entered at dp[i]d**p[i]. Thus, instead of making use of a 1-D array to store the required data, we can simply keep a track of just the last element.
Complexity Analysis
Time complexity : O(n)O(n). We traverse over the given AA array with nn elements once only.
Space complexity : O(1)O(1). Constant extra space is used.
Approach #6 Using Formula [Accepted]:
Algorithm
From the dpd**p solution, we can observe that for kk consecutive elements sastisfying the common difference criteria, we update the sumsum for each such element by 1,2,3,…,k1,2,3,…,k counts in that order. Thus, instead of updating the sumsum at the same time, we can just keep a track of the number of consecutive elements satisfying the common differnce criteria in a countcount variable and just update the sumsum directly as count∗(count+1)/2count∗(count+1)/2 whenver an element not satisfying this criteria is found. At the same time, we also need to reset the countcount value.
Complexity Analysis
Time complexity : O(n)O(n). We iterate over AA with nn elements exactly once.
Space complexity : O(1)O(1). Constant extra space is used.
dp[i][j]表示从i到j序列的最低分。记底边为ij的三角形顶点为m,三角形imj将多边形分成三部分,总分即为三部分的分数和(如果m=i+1或m=j-1,则对应第一或第三部分分数为0)。 那么m在什么位置分数最低呢,将m从i+1到j-1遍历,分别计算dp[i][m]+A[i]A[j]A[m]+dp[m][j],取其中最小值即为dp[i][j]。 dp[i][j]=min(dp[i][m]+A[i]A[j]A[m]+dp[m][j]),for m in range [i+1,j-1]
class Solution { private Integer[] cache = new Integer[31];
public int fib(int N) { if (N <= 1) { return N; } cache[0] = 0; cache[1] = 1; return memoize(N); }
public int memoize(int N) { if (cache[N] != null) { return cache[N]; } cache[N] = memoize(N-1) + memoize(N-2); return memoize(N); } }
Approach 1: Recursion
Intuition
Use recursion to compute the Fibonacci number of a given integer.
Figure 1. An example tree representing what fib(5) would look like
Algorithm
Check if the provided input value, N, is less than or equal to 1. If true, return N.
Otherwise, the function fib(int N) calls itself, with the result of the 2 previous numbers being added to each other, passed in as the argument. This is derived directly from the recurrence relation: Fn=Fn−1+Fn−2F**n=F*n−1+F*n−2
Do this until all numbers have been computed, then return the resulting answer.
Complexity Analysis
Time complexity : O(2N)O(2N). This is the slowest way to solve the Fibonacci Sequence because it takes exponential time. The amount of operations needed, for each level of recursion, grows exponentially as the depth approaches N.
Space complexity : O(N)O(N). We need space proportionate to N to account for the max size of the stack, in memory. This stack keeps track of the function calls to fib(N). This has the potential to be bad in cases that there isn’t enough physical memory to handle the increasingly growing stack, leading to a StackOverflowError. The Java docs have a good explanation of this, describing it as an error that occurs because an application recurses too deeply.
Approach 2: Bottom-Up Approach using Memoization
Intuition
Improve upon the recursive option by using iteration, still solving for all of the sub-problems and returning the answer for N, using already computed Fibonacci values. In using a bottom-up approach, we can iteratively compute and store the values, only returning once we reach the result.
Algorithm
If N is less than or equal to 1, return N
Otherwise, iterate through N, storing each computed answer in an array along the way.
Use this array as a reference to the 2 previous numbers to calculate the current Fibonacci number.
Once we’ve reached the last number, return it’s Fibonacci number.
Complexity Analysis
Time complexity : O(N)O(N). Each number, starting at 2 up to and including N, is visited, computed and then stored for O(1)O(1)access later on.
Space complexity : O(N)O(N). The size of the data structure is proportionate to N.
Approach 3: Top-Down Approach using Memoization
Intuition
Solve for all of the sub-problems, use memoization to store the pre-computed answers, then return the answer for N. We will leverage recursion, but in a smarter way by not repeating the work to calculate existing values.
Algorithm
Check if N <= 1. If it is, return N.
Call and return memoize(N)
If N exists in the map, return the cached value for N
Otherwise set the value of N, in our mapping, to the value of memoize(N-1) + memoize(N-2)
Complexity Analysis
Time complexity : O(N)O(N). Each number, starting at 2 up to and including N, is visited, computed and then stored for O(1)O(1)access later on.
Space complexity : O(N)O(N). The size of the stack in memory is proportionate to N.
Approach 4: Iterative Top-Down Approach
Intuition
Let’s get rid of the need to use all of that space and instead use the minimum amount of space required. We can achieve O(1)O(1)space complexity by only storing the value of the two previous numbers and updating them as we iterate to N.
Algorithm
Check if N <= 1, if it is then we should return N.
Check if N == 2, if it is then we should return 1 since N is 2 and fib(2-1) + fib(2-2) equals 1 + 0 = 1.
To use an iterative approach, we need at least 3 variables to store each state fib(N), fib(N-1) and fib(N-2).
Preset the initial values:
Initialize current with 0.
Initialize prev1 with 1, since this will represent fib(N-1) when computing the current value.
Initialize prev2 with 1, since this will represent fib(N-2) when computing the current value.
Iterate, incrementally by 1, all the way up to and including N. Starting at 3, since 0, 1 and 2 are pre-computed.
Set the current value to fib(N-1) + fib(N-2) because that is the value we are currently computing.
Set the prev2 value to fib(N-1).
Set the prev1 value to current_value.
When we reach N+1, we will exit the loop and return the previously set current value.
Complexity Analysis
Time complexity : O(N)O(N). Each value from 2 to N will be visited at least once. The time it takes to do this is directly proportionate to N where N is the Fibonacci Number we are looking to compute.
Space complexity : O(1)O(1). This requires 1 unit of Space for the integer N and 3 units of Space to store the computed values (curr, prev1 and prev2) for every loop iteration. The amount of Space doesn’t change so this is constant Space complexity.
Approach 5: Matrix Exponentiation
Intuition
Use Matrix Exponentiation to get the Fibonacci number from the element at (0, 0) in the resultant matrix.
In order to do this we can rely on the matrix equation for the Fibonacci sequence, to find the Nth Fibonacci number: (1 11 0)n=( F(n+1) F(n) F(n) F(n−1))(1110)n=(F(n+1)F(n)F(n)F(n−1))
Algorithm
Check if N is less than or equal to 1. If it is, return N.
Use a recursive function, matrixPower, to calculate the power of a given matrix A. The power will be N-1, where N is the Nth Fibonacci number.
The matrixPower function will be performed for N/2 of the Fibonacci numbers.
Within matrixPower, call the multiply function to multiply 2 matrices.
Once we finish doing the calculations, return A[0][0] to get the Nth Fibonacci number.
Complexity Analysis
Time complexity : O(logN)O(logN). By halving the N value in every matrixPower‘s call to itself, we are halving the work needed to be done.
Space complexity : O(logN)O(logN). The size of the stack in memory is proportionate to the function calls to matrixPower plus the memory used to account for the matrices which takes up constant space.
Approach 6: Math
Intuition Using the golden ratio, a.k.a Binet's forumula: φ=1+52≈1.6180339887….φ=21+5≈1.6180339887….
Here’s a link to find out more about how the Fibonacci sequence and the golden ratio work.
We can derive the most efficient solution to this problem using only constant time and constant space!
Algorithm
Use the golden ratio formula to calculate the Nth Fibonacci number.
Complexity Analysis
Time complexity : O(1)O(1). Constant time complexity since we are using no loops or recursion and the time is based on the result of performing the calculation using Binet's formula.
Space complexity : O(1)O(1). The space used is the space needed to create the variable to store the golden ratio formula.
classNumMatrix{ privateint[][] dp; publicNumMatrix(int[][] matrix){ if(matrix.length==0 || matrix[0].length==0) return; int r=matrix.length; int c=matrix[0].length; dp=newint[r+1][c+1]; for(int i=0;i<r;i++){ for(int j=0;j<c;j++){ dp[i+1][j+1]=dp[i][j+1]+dp[i+1][j]+matrix[i][j]-dp[i][j]; } } } publicintsumRegion(int row1, int col1, int row2, int col2){ return dp[row2+1][col2+1]-dp[row1][col2+1]-dp[row2+1][col1]+dp[row1][col1]; } }
/** * Your NumMatrix object will be instantiated and called as such: * NumMatrix obj = new NumMatrix(matrix); * int param_1 = obj.sumRegion(row1,col1,row2,col2); */
//dp真慢 classSolution{ publicintlengthOfLIS(int[] nums){ int len=nums.length; if(len<=0) return0; int[] dp=newint[len]; dp[0]=1; int maxans=1; for(int i=1;i<len;i++){ int maxval=0; for(int j=0;j<i;j++){ if(nums[i]>nums[j]) maxval=Math.max(maxval,dp[j]); dp[i]=maxval+1; maxans=Math.max(maxans,dp[i]); } } return maxans; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
publicclassSolution{//binary search加dp真香 publicintlengthOfLIS(int[] nums){ int[] dp = newint[nums.length]; int len = 0; for (int num : nums) { int i = Arrays.binarySearch(dp, 0, len, num); if (i < 0) { i = -(i + 1); } dp[i] = num; if (i == len) { len++; } } return len; } }