模块
module:一个 .py 文件就是个 module
lib:抽象概念,和另外两个不zhidao是一类,只要你喜欢,什么都是 lib,就算只有个 hello world
package:就是个带 init.py 的文件夹,并不在乎里内面有什么,不过一般来讲会包含一些 packages/modules
scrapy、flask、Django、numpy、scipy、NLTK、jieba一般都被认为是 lib,因为关注点并不是代码是怎么组织容的。
- Python 程序由模块组成。一个模块对应 python 源文件,一般后缀名是:.py。
- 模块由语句组成。运行 Python 程序时,按照模块中语句的顺序依次执行。
- 语句是 Python 程序的构造单元,用于创建对象、变量赋值、调用函数、控制语句等。
1.python模块是:
python模块:包含并且有组织的代码片段为模块。
表现形式为:写的代码保存为文件。这个文件就是一个模块。sample.py 其中文件名smaple为模块名字。
关系图:

2.python包是:
包是一个有层次的文件目录结构,它定义了由n个模块或n个子包组成的python应用程序执行环境。通俗一点:包是一个包含init.py 文件的目录,该目录下一定得有这个init.py文件和其它e68a84e79fa5e9819331333365656638模块或子包。
常见问题:
引入某一特定路径下的模块
使用sys.path.append(yourmodulepath)
将一个路径加入到python系统路径下,避免每次通过代码指定路径
利用系统环境变量 export PYTHONPATH=$PYTHONPATH:yourmodulepath,
直接将这个路径链接到类似/Library/Python/2.7/site-packages目录下
好的建议:
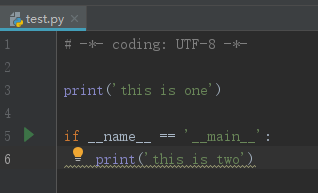
经常使用if name == ‘main‘,保证写包既可以import又可以独立运行,用于test。
多次import不会多次执行模块,只会执行一次。可以使用reload来强制运行模块,但不提倡。
常见的包结构如下:
package_a├── init.py├── module_a1.py└── module_a2.pypackage_b├── init.py├── module_b1.py└── module_b2.py
main.py
如果main.py想要引用packagea中的模块modulea1,可以使用:
from package_a import module_a1
import package_a.module_a1
如果packagea中的modulea1需要引用packageb,那么默认情况下,python是找不到packageb。我们可以使用sys.path.append(‘../‘),可以在packagea中的init.py添加这句话,然后该包下得所有module都添加* import __init_即可。
关系图:

3.库(library)
库的概念是具有相关功能模块的集合。这也是Python的一大特色之一,即具有强大的标准库、第三方库以及自定义模块。
1.2 标准库模块(standard library)
与函数类似,模块也分为标准库模块和用户自定义模块。
Python 标准库提供了操作系统功能、网络通信、文本处理、文件处理、数学运算等基 本的功能。比如:random(随机数)、math(数学运算)、time(时间处理)、file(文件处理)、 os(和操作系统交互)、sys(和解释器交互)等。
另外,Python 还提供了海量的第三方模块,使用方式和标准库类似。功能覆盖了我们 能想象到的所有领域,比如:科学计算、WEB 开发、大数据、人工智能、图形系统等。
模块化编程有如下几个重要优势:
\1. 便于将一个任务分解成多个模块,实现团队协同开发,完成大规模程序 2. 实现代码复用。一个模块实现后,可以被反复调用。
\3. 可维护性增强。
1.4 模块化编程的流程
模块化编程的一般流程:
\1. 设计 API,进行功能描述
\2. 编码实现 API 中描述的功能。
\3. 在模块中编写测试代码,并消除全局代码。
\4. 使用私有函数实现不被外部客户端调用的模块函数。
API(Application Programming Interface 应用程序编程接口)是用于描述模 块中提供的函数和类的功能描述和使用方式描述。
模块化编程中,首先设计的就是模块的 API(即要实现的功能描述),然后开始编 码实现 API 中描述的功能。最后,在其他模块中导入本模块进行调用。
我们可以通过help(模块名)查看模块的API。一般使用时先导入模块 然后通过help函数查看
1 | import math |
设计计算薪水模块的 API
1 | """ |
如上模块只有功能描述和规范,需要编码人员按照要求实现编码。 我们可以通过doc可以获得模块的文档字符串的内容。
test.py 的源代码:
1 | import salary |
运行结果:
本模块用于计算公司员工的薪资
根据传入的月薪,计算出年薪
模块的创建和测试代码
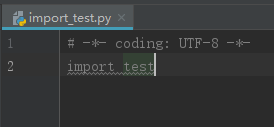
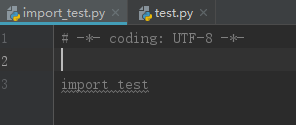
每个模块都有一个名称,通过特殊变量name可以获取模块的名称。在正常情况下,模块名字对应源文件名。 仅有一个例外,就是当一个模块被作为程序入口时(主 程序、交互式提示符下),它的name的值为“main”。我们可以根据这个特 点,将模块源代码文件中的测试代码进行独立的处理。例如:
1 | import math |
1 | company = "北京尚学堂" |
1.7 模块文档字符串和 API 设计
我们可以在模块的第一行增加一个文档字符串,用于描述模块的相关功能。然后,通过 doc可以获得文档字符串的内容。
2. 模块的导入
模块化设计的好处之一就是“代码复用性高”。写好的模块可以被反复调用,重复使用。 模块的导入就是“在本模块中使用其他模块”。
2.1 import 语句导入
import 语句的基本语法格式如下: import 模块名
import 模块 1,模块 2… import 模块名 as 模块别名
#导入一个模块 #导入多个模块
#导入模块并使用新名字
import 加载的模块分为四个通用类别:
a.使用 python 编写的代码(.py 文件); b.已被编译为共享库或 DLL 的 C 或 C++扩展; c.包好一组模块的包
d.使用 C 编写并链接到 python 解释器的内置模块;
我们一般通过 import 语句实现模块的导入和使用,import 本质上是使用了内置函数 import()。
当我们通过 import 导入一个模块时,python 解释器进行执行,最终会生成一个对象, 这个对象就代表了被加载的模块。
我们可以看到 math 模块被加载后,实际会生成一个 module 类的对象,该对象被 math 变量引用。我们可以通过 math 变量引用模块中所有的内容。
我们通过 import 导入多个模块,本质上也是生成多个 module 类的对象而已。
有时候,我们也需要给模块起个别名,本质上,这个别名仅仅是新创建一个变量引用加 载的模块对象而已。
2.2 from…import 导入
Python 中可以使用 from…import 导入模块中的成员。基本语法格式如下: from 模块名 import 成员 1,成员 2,…
如果希望导入一个模块中的所有成员,则可以采用如下方式: from 模块名 import *
【注】尽量避免“from 模块名 import ”这种写法。 它表示导入模块中所有的不 是以下划线(_)开头的名字都导入到当前位置。 但你不知道你导入什么名字,很有可能 会覆盖掉你之前已经定义的名字。而且可读性极其的差。一般生产环境中尽量避免使用, 学习时没有关系。
2.3 import 语句和 from…import 语句的区别
import 导入的是模块。from…import 导入的是模块中的一个函数/一个类。
如果进行类比的话,import 导入的是“文件”,我们要使用该“文件”下的内容,必 须前面加“文件名称”。from…import 导入的是文件下的“内容”,我们直接使用这 些“内容”即可,前面再也不需要加“文件名称”了。
2.4 import()动态导入
import 语句本质上就是调用内置函数import(),我们可以通过它实现动态导入。给 import()动态传递不同的的参数值,就能导入不同的模块。
1 | s = "math" |
注意:一般不建议我们自行使用import()导入,其行为在 python2 和 python3 中 有差异,会导致意外错误。如果需要动态导入可以使用 importlib 模块。
1 | import importlib |
2.5 模块的加载问题
当导入一个模块时, 模块中的代码都会被执行。不过,如果再次导入这个模块, 则不会再次执行。
Python 的设计者为什么这么设计?因为,导入模块更多的时候需要的是定义模块 中的变量、函数、对象等。这些并不需要反复定义和执行。“只导入一次 import-only-once”就成了一种优化。
一个模块无论导入多少次,这个模块在整个解释器进程内有且仅有一个实例对象。
重新加载 有时候我们确实需要重新加载一个模块,这时候可以使用:**importlib.reload()**
方法:
1 | import test02 |
3. 包 package 的使用
3.1 包(package)的概念和结构
1 | 当一个项目中有很多个模块时,需要再进行组织。我们将功能类似的模块放到一起, 形成了“包”。本质上,“包”就是一个必须有__init__.py 的文件夹。典型结构如下: |
包下面可以包含“模块(module)”,也可以再包含“子包(subpackage)”。就像文件 夹下面可以有文件,也可以有子文件夹一样。
1 | ,a 是上层的包,下面有一个子包:aa。可以看到每个包里面都有__init__.py 文件。 |
3.2 pycharm 中创建包
在 pycharm 开发环境中创建包,非常简单。在要创建包的地方单击右键:New–>Python package 即可。pycharm 会自动帮助我们生成带有init.py 文件的包。
3.3 导入包操作和本质
上一节中的包结构,我们需要导入 module_AA.py。方式如下:
import a.aa.module_AA
在使用时,必须加完整名称来引用,比如:a.aa.module_AA.fun_AA()
from a.aa import module_AA
在使用时,直接可以使用模块名。 比如:module_AA.fun_AA()
from a.aa.module_AA import fun_AA 直接导入函数
在使用时,直接可以使用函数名。 比如:fun_AA()
【注】
\1. from package import item 这种语法中,item 可以是包、模块,也可以是函数、类、变量。
\2. import item1.item2 这种语法中,item 必须是包或模块,不能是其他。
1 | 导入包的本质其实是“导入了包的__init__.py”文件。也就是说,”import pack1”意味 着执行了包 pack1 下面的__init__.py 文件。 这样,可以在__init__.py 中批量导入我们需要 的模块,而不再需要一个个导入。 |
可以说“包的本质还是模块”。
3.4 用*导入包
import * 这样的语句理论上是希望文件系统找出包中所有的子模块,然后导入它们。 这可能会花长时间等。Python 解决方案是提供一个明确的包索引。
这个索引由 init.py 定义 all 变量,该变量为一列表,如上例 a 包下的 init.py 中,可定义 all = [“module_A”,”module_A2”]
这意味着, from sound.effects import * 会从对应的包中导入以上两个子模块;
【注】尽管提供 import * 的方法,仍不建议在生产代码中使用这种写法。
3.5 包内引用
如果是子包内的引用,可以按相对位置引入子模块 以 aa 包下的 module_AA 中导入 a 包下内容为例:
from .. import module_A #..表示上级目录 .表示同级目录
from . import module_A2 #.表示同级目录
3.6 sys.path 和模块搜索路径
当我们导入某个模块文件时, Python 解释器去哪里找这个文件呢?只有找到这个文 件才能读取、装载运行该模块文件。它一般按照如下路径寻找模块文件(按照顺序寻找,找 到即停不继续往下寻找):
\1. 内置模块
\2. 当前目录
\3. 程序的主目录
\4. pythonpath 目录(如果已经设置了 pythonpath 环境变量) 5. 标准链接库目录
\6. 第三方库目录(site-packages 目录)
\7. .pth 文件的内容(如果存在的话)
\8. sys.path.append()临时添加的目录
当任何一个 python 程序启动时,就将上面这些搜索路径(除内置模块以外的路径)进行收集, 放到 sys 模块的 path 属性中(sys.path)。
使用 sys.path 查看和临时修改搜索路径
1 | import sys |
4. 模块发布和安装
4.1 模块的本地发布**
当我们完成了某个模块开发后,可以将他对外发布,其他开发者也可以以“第三方扩展 库”的方式使用我们的模块。我们按照如下步骤即可实现模块的发布:
1.为模块文件创建如下结构的文件夹(一般,文件夹的名字和模块的名字一样):
2.在文件夹中创建一个名为『setup.py』的文件
\3. 构建一个发布文件。通过终端,cd 到模块文件夹 c 下面,再键入命令:
python setup.py sdist
4.3 上传模块到 PyPI
将自己开发好的模块上传到 PyPI 网站上,将成为公开的资源,可以让全球用户自由使 用。按照如下步骤做,很容易就实现上传模块操作。
·管理你的模块
4.4 让别人使用你的模块
模块发布完成后,其他人只需要使用 pip 就可以安装你的模块文件。比如:
pip install package-name
5. 库(Library)
Python 中库是借用其他编程语言的概念,没有特别具体的定义。模块和包侧重于代码 组织,有明确的定义。
一般情况,库强调的是功能性,而不是代码组织。我们通常将某个功能的“模块的集合”, 称为库。
5.1 标准库(Standard Library)
Python 拥有一个强大的标准库。Python 语言的核心只包含数字、字符串、列表、字典、 文件等常见类型和函数,而由 Python 标准库提供了系统管理、网络通信、文本处理、数据 库接口、图形系统、XML 处理等额外的功能。
Python 标准库的主要功能有:
\1. 文本处理,包含文本格式化、正则表达式匹配、文本差异计算与合并、Unicode 支 持,二进制数据处理等功能
\2. 文件处理,包含文件操作、创建临时文件、文件压缩与归档、操作配置文件等功能
\3. 操作系统功能,包含线程与进程支持、IO 复用、日期与时间处理、调用系统函数、 日志(logging)等功能
\4. 网络通信,包含网络套接字,SSL 加密通信、异步网络通信等功能
\5. 网络协议,支持 HTTP,FTP,SMTP,POP,IMAP,NNTP,XMLRPC 等多种网 络协议,并提供了编写网络服务器的框架
\6. W3C 格式支持,包含 HTML,SGML,XML 的处理
\7. 其它功能,包括国际化支持、数学运算、HASH、Tkinter 等
目前学过的有:random、math、time、file、os、sys 等模块。可以通过 random 模 块实现随机数处理、math 模块实现数学相关的运算、time 模块实现时间的处理、file 模块 实现对文件的操作、OS 模块实现和操作系统的交互、sys 模块实现和解释器的交互。
5.2 第三方扩展库的介绍
强大的标准库奠定了 python 发展的基石,丰富和不断扩展的第三方库是 python 壮大 的保证。我们可以进入 PyPI 官网:
常用第三方库大汇总
| 分类 | 库名称 | 说明 |
|---|---|---|
| 环境管理 | P | 非常简单的交互式 python 版本管理工具 |
| Pyenv | 简单的 Python 版本管理工具 | |
| Vex | 可以在虚拟环境中执行命令 |
|
| Virtualenv virtualenvwrapp | 创建独立 Python 环境的工具 |
尚学堂·百战程序员 www.itbaizhan.cn
| er | ||
|---|---|---|
| 包管理 | pip | Python 包和依赖关系管理工具 |
| pip-tools | 保证 Python 包依赖关系更新的一组工具 | |
| Pipenv | Python 官方推荐的新一代包管理工具 | |
| Poetry | 可完全取代 setup.py 的包管理工具 | |
| 包仓库 | warehouse | 下一代 PyPI |
| Devpi | PyPI 服务和打包/测试/分发工具 | |
| 分发 (打包为可执行文件 以便分发) | PyInstaller | 将 Python 程序转成独立的执行文件(跨平台) |
| Nuitka | 将脚本、模块、包编译成可执行文件或扩展模块 | |
| py2app | 将 Python 脚本变为独立软件包(Mac OS X) | |
| py2exe | 将 Python 脚本变为独立软件包(Windows) | |
| pynsist | 一个用来创建 Windows 安装程序的工具,可 以在安装程序中打包 Python 本身 | |
| 构建工具 (将源码编译成软件) | Buildout | 构建系统,从多个组件来创建,组装和部署应用 |
| BitBake | 针对嵌入式 Linux 的类似 make 的构建工具 | |
| Fabricate | 对任何语言自动找到依赖关系的构建工具 |
|
| 交互式 Python 解 析器 | IPython | 功能丰富的工具,非常有效的使用交互式 Python |
| bpython | 界面丰富的 Python 解析器 | |
| Ptpython | 高级交互式 Python 解析器,构建 于 python-prompt-toolkit 之上 | |
| 文件管理 | Aiofiles | 基于 asyncio,提供文件异步操作 |
| Imghdr | (Python 标准库)检测图片类型 | |
| Mimetypes | (Python 标准库)将文件名映射为 MIME 类型 | |
| path.py | 对 os.path 进行封装的模块 | |
| Pathlib | (Python3.4+ 标准库)跨平台的、面向对象的 路径操作库 | |
| Unipath | 用面向对象的方式操作文件和目录 |
|
| Watchdog | 管理文件系统事件的 API 和 shell 工具 | |
| 日期和时间 | Arrow | 更好的 Python 日期时间操作类库 |
| Chronyk | 解析手写格式的时间和日期 |
|
| Dateutil | Python datetime 模块的扩展 | |
| PyTime | 一个简单易用的 Python 模块,用于通过字符 串来操作日期/时间 | |
| when.py | 提供用户友好的函数来帮助用户进行常用的日 期和时间操作 | |
| 文本处理 | chardet | 字符编码检测器,兼容 Python2 和 Python3 |
尚学堂·百战程序员 www.itbaizhan.cn
| Difflib | (Python 标准库)帮助我们进行差异化比较 | |
|---|---|---|
| Fuzzywuzzy | 模糊字符串匹配 | |
| Levenshtein | 快速计算编辑距离以及字符串的相似度 |
|
| Pypinyin | 汉字拼音转换工具 Python 版 | |
| Shortuuid | 一个生成器库,用以生成简洁的,明白的,URL 安全的 UUID | |
| simplejson | Python 的 JSON 编码、解码器 | |
| Unidecode | Unicode 文本的 ASCII 转换形式 | |
| Xpinyin | 一个用于把汉字转换为拼音的库 | |
| Pygment | 通用语法高亮工具 | |
| Phonenumbers | 解析,格式化,储存,验证电话号码 | |
| Sqlparse | 一个无验证的 SQL 解析器 | |
| 特殊文本格式处理 | Tablib | 一个用来处理中表格数据的模块 |
| Pyexcel | 用来读写,操作 Excel 文件的库 | |
| python-docx | 读取,查询以及修改 word 文件 | |
| PDFMiner | 一个用于从 PDF 文档中抽取信息的工具 | |
| Python-Markdo wn2 | 纯 Python 实现的 Markdown 解析器 | |
| Csvkit | 用于转换和操作 CSV 的工具 | |
| 自然语言处理 | NLTK | 一个先进的平台,用以构建处理人类语言数据的 Python 程序 |
| Jieba | 中文分词工具 | |
| langid.py | 独立的语言识别系统 | |
| SnowNLP | 一个用来处理中文文本的库 | |
| Thulac | 清华大学自然语言处理与社会人文计算实验室 研制推出的一套中文词法分析工具包 | |
| 下载器 | you-get | 一个 YouTube/Youku/Niconico 视频下载器 |
| 图像处理 | pillow | 最常用的图像处理库 |
| imgSeek | 一个使用视觉相似性搜索一组图片集合的项目 | |
| face_recognition | 简单易用的 python 人脸识别 | |
| python-qrcode | 一个纯 Python 实现的二维码生成器 | |
| OCR | Pyocr | Tesseract 和 Cuneiform 的 一 个 封 装 (wrapper) |
| pytesseract | Google Tesseract OCR 的 另 一 个 封 装 |
尚学堂·百战程序员 www.itbaizhan.cn
| (wrapper) | ||
|---|---|---|
| 音频处理 | Audiolazy | Python 的数字信号处理包 |
| Dejavu | 音频指纹提取和识别 | |
| id3reader | 一个用来读取 MP3 元数据的 Python 模块 | |
| TimeSide | 开源 web 音频处理框架 | |
| Tinytag | 一个用来读取 MP3, OGG, FLAC 以及 Wave 文件音乐元数据的库 | |
| Mingus | 一个高级音乐理论和曲谱包,支持 MIDI 文件 和回放功能 | |
| 视频和 GIF 处理 | Moviepy | 一个用来进行基于脚本的视频编辑模块,适用于 多种格式,包括动图 GIFs |
| scikit-video | SciPy 视频处理常用程序 | |
| 地理位置 | GeoDjango | 世界级地理图形 web 框架 |
| GeoIP | MaxMind GeoIP Legacy 数 据 库 的 Python API | |
| Geopy | Python 地址编码工具箱 | |
| HTTP | requests | 人性化的 HTTP 请求库 |
| httplib2 | 全面的 HTTP 客户端库 | |
| urllib3 | 一个具有线程安全连接池,支持文件 post,清 晰友好的 HTTP 库 | |
| Python 实现的 数据库 | pickleDB | 一个简单,轻量级键值储存数据库 |
| PipelineDB | 流式 SQL 数据库 | |
| TinyDB | 一个微型的,面向文档型数据库 | |
| web 框架 | Django | Python 界最流行的 web 框架 |
| Flask | 一个 Python 微型框架 | |
| Tornado | 一个 web 框架和异步网络库 | |
| CMS 内容管理系统 | odoo-cms | 一个开源的,企业级 CMS,基于 odoo |
| djedi-cms | 一个轻量级但却非常强大的 Django CMS ,考 虑到了插件,内联编辑以及性能 | |
| Opps | 一个为杂志,报纸网站以及大流量门户网站设计 的 CMS 平台,基于 Django | |
| 电子商务和支付系 统 | django-oscar | 一个用于 Django 的开源的电子商务框架 |
| django-shop | 一个基于 Django 的店铺系统 | |
| Shoop | 一个基于 Django 的开源电子商务平台 | |
| Alipay | Python 支付宝 API | |
| Merchant | 一个可以接收来自多种支付平台支付的 |
尚学堂·百战程序员 www.itbaizhan.cn
| Django 应用 | ||
|---|---|---|
| 游戏开发 | Cocos2d | 用来开发 2D 游戏 |
| Panda3D | 由迪士尼开发的 3D 游戏引擎,并由卡内基梅 陇娱乐技术中心负责维护。使用 C++ 编写, 针 对 Python 进行了完全的封装 | |
| Pygame | Pygame 是一组 Python 模块,用来编写游戏 | |
| RenPy | 一个视觉小说(visual novel)引擎 | |
| 计算机视觉库 | OpenCV | 开源计算机视觉库 |
| Pyocr | Tesseract 和 Cuneiform 的包装库 | |
| SimpleCV | 一个用来创建计算机视觉应用的开源框架 | |
| 机器学习 人工智能 | TensorFlow | 谷歌开源的最受欢迎的深度学习框架 |
| keras | 以 tensorflow/theano/CNTK 为 后 端 的 深 度 学习封装库,快速上手神经网络 | |
| Hebel | GPU 加速的深度学习库 | |
| Pytorch | 一个具有张量和动态神经网络,并有强大 GPU 加速能力的深度学习框架 | |
| scikit-learn | 基于 SciPy 构建的机器学习 Python 模块 | |
| NuPIC | 智能计算 Numenta 平台 | |
| 科学计算和数据分 析 | NumPy | 使用 Python 进行科学计算的基础包 |
| Pandas | 提供高性能,易用的数据结构和数据分析工具 | |
| SciPy | 用于数学,科学和工程的开源软件构成的生态系 统 | |
| PyMC | 马尔科夫链蒙特卡洛采样工具 |
|
| 代码分析和调试 | code2flow | 把你的 Python 和 JavaScript 代码转换为流 程图 |
| Pycallgraph | 这个库可以把你的 Python 应用的流程(调用 图)进行可视化 | |
| Pylint | 一个完全可定制的源码分析器 | |
| autopep8 | 自动格式化 Python 代码,以使其符合 PEP8 规范 | |
| Wdb | 一个奇异的 web 调试器,通过 WebSockets 工作 | |
| Lineprofiler | 逐行性能分析 | |
| Memory Profiler | 监控 Python 代码的内存使用 | |
| 图形用户界面 | Pyglet | 一个 Python 的跨平台窗口及多媒体库 |
尚学堂·百战程序员 www.itbaizhan.cn
| PyQt | 跨平台用户界面框架 Qt 的 Python 绑定 ,支 持 Qtv4 和 Qtv5 | |
|---|---|---|
| Tkinter | Tkinter 是 Python GUI 的一个事实标准库 | |
| wxPython | wxPython 是 wxWidgets C++ 类 库 和 Python 语言混合的产物 | |
| 网络爬虫和 HTML 分析 | Scrapy | 一个快速高级的屏幕爬取及网页采集框架 |
| Cola | 一个分布式爬虫框架 | |
| Grab | 站点爬取框架 | |
| Pyspider | 一个强大的爬虫系统 | |
| html2text | 将 HTML 转换为 Markdown 格式文本 | |
| python-goose | HTML 内容/文章提取器 | |
| 硬件编程 | Ino | 操作 Arduino 的命令行工具 |
| Pyro | Python 机器人编程库 | |
| PyUserInput | 跨平台的,控制鼠标和键盘的模块 | |
| Pingo | Pingo 为类似 RaspberryPi,pcDuino,Intel Galileo 等设备提供统一的 API |
5.4 安装第三方扩展库的 2 种方式
第三方库有数十万种之多,以 pillow 库为例讲解第三方扩展库的安装。pillow 是 Python 平台事实上的图像处理标准库,本节以安装 pillow 为例,给大家介绍第三方库的两 种常用的安装方法。
尚学堂·百战程序员 www.itbaizhan.cn
第一种方式:命令行下远程安装
以安装第三方 pillow 图像库为例,在命令行提示符下输入:pip 安装完成后,我们就可以开始使用。
第二种方式:Pycharm 中直接安装到项目中
在 Pycharm 中,依次点击:file–>setting–>Project 本项目名–>Project Interpreter