异常和错误
软件程序在运行过程中,非常可能遇到刚刚提到的这些问题,我们称之为 异常,英文是:Exception,意思是例外。
异常机制本质
异常指程序运行过程中出现的非正常现象,例如用户输入错误、除数为零、需 要处理的文件不存在、数组下标越界等。
所谓异常处理,就是指程序在出现问题时依然可以正确的执行剩余的程序,而 不会因为异常而终止程序执行。
python 中,引进了很多用来描述和处理异常的类,称为异常类。异常类定义中 包含了该类异常的信息和对异常进行处理的方法。
python 中内建异常类的继承层次:
1 | BaseException:所以异常的父类 |
python 中一切都是对象,异常也采用对象的方式来处理。处理过程:
抛出异常:在执行一个方法时,如果发生异常,则这个方法生成代表该异常的一个对象,停止当前执行路径,并把异常对象提交给解释器。
捕获异常:解释器得到该异常后,寻找相应的代码来处理该异常。
异常解决的关键:定位
当发生异常时,解释器会报相关的错误信息,并会在控制台打印出相关错误信息。我们 只需按照从上到下的顺序即可追溯(Trackback)错误发生的过程,最终定位引起错误的那一 行代码。
try… 一个except 结构
try…except 是最常见的异常处理结构。结构如下:
1 | try: |
try 块包含着可能引发异常的代码,except 块则用来捕捉和处理发生的异常。执行的时 候,如果 try 块中没有引发异常,则跳过 ecept 块继续执行后续代码;执行的时候,如果 try块中发生了异常,则跳过 try 块中的后续代码,跳到相应的 except 块中处理异常;异常处理 完后,继续执行后续代码。
例子
1 | try: |
结果:
1 | step1 |
例子2
1 | try: |
#结果
step1
step2
step4
try…多个 except 结构
上面的结构可以捕获所有的异常,工作中也很常见。但是,从经典理论考虑,一般建议 尽量捕获可能出现的多个异常(按照先子类后父类的顺序),并且针对性的写出异常处理代 码。为了避免遗漏可能出现的异常,可以在最后增加 BaseException。结构如下:
1 | try: |
例
1 | try: |
try…except…else 结构
try…except…else 结构增加了“else 块”。如果 try 块中没有抛出异常,则执行 else 块。如果
try 块中抛出异常,则执行 except 块,不执行 else 块。
1 | 发生异常的执行情况(执行 except 块,没有执行 else): |
try…except…finally 结构
try…except…finally 结构中,finally 块无论是否发生异常都会被执行;通常用来释放 try 块中申请的资源
finally 中的语句,无论是否发生异常都执行
读取文件,finally 中保证关闭文件资源
1 | try: |
需要把f.close也try except
return 语句和异常处理问题
由于 return 有两种作用:结束方法运行、返回值。我们一般不把 return 放到异常处理结构
中,而是放到方法最后。
一般不要将 return 语句放到 try、except、else、finally 块中,会发生一些意想不到的错误。建议放到方法最后。
常见异常的解决
Python 中的异常都派生自 BaseException 类
\1. SyntaxError:语法错误
1 | int a =3 |
\2. NameError:尝试访问一个没有申明的变量
1 | print(a) |
\3. ZeroDivisionError:除数为0错误(零除错误)
1 | a = 3/0 |
\4. ValueError:数值错误
1 | float("gaoqi") |
\5. TypeError:类型错误
1 | 123+"abc" |
\6. AttributeError:访问对象的不存在的属性
1 | a.sayhi() |
\7. IndexError:索引越界异常
1 | a[10] |
\8. KeyError:字典的关键字不存在
1 | a['salary'] KeyError: 'salary' |
| 异常名称 | 说明 |
|---|---|
ArithmeticError |
所有数值计算错误的基类 |
AssertionError |
断言语句失败 |
AttributeError |
对象没有这个属性 |
BaseException |
所有异常的基类 |
DeprecationWarning |
关于被弃用的特征的警告 |
EnvironmentError |
操作系统错误的基类 |
| EOFError | 没有内建输入,到达 EOF 标记 |
| Exception | 常规错误的基类 |
FloatingPointError |
浮点计算错误 |
FutureWarning |
关于构造将来语义会有改变的警告 |
GeneratorExit |
生成器(generator)发生异常来通知退出 |
| ImportError | 导入模块/对象失败 |
IndentationError |
缩进错误 |
| IndexError | 序列中没有此索引(index) |
| IOError | 输入/输出操作失败 |
KeyboardInterrupt |
用户中断执行(通常是输入^C) |
|---|---|
| KeyError | 映射中没有这个键 |
| LookupError | 无效数据查询的基类 |
| MemoryError | 内存溢出错误(对于 Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
NotImplementedError |
尚未实现的方法 |
| OSError | 操作系统错误 |
OverflowError |
数值运算超出最大限制 |
OverflowWarning |
旧的关于自动提升为长整型(long)的警告 |
PendingDeprecationWarning |
关于特性将会被废弃的警告 |
ReferenceError |
弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
RuntimeError |
一般的运行时错误 |
RuntimeWarning |
可疑的运行时行为(runtime behavior)的警告 |
StandardError |
所有的内建标准异常的基类 |
StopIteration |
迭代器没有更多的值 |
| SyntaxError | Python 语法错误 |
SyntaxWarning |
可疑的语法的警告 |
| SystemError | 一般的解释器系统错误 |
| SystemExit | 解释器请求退出 |
| TabError | Tab 和空格混用 |
| TypeError | 对类型无效的操作 |
UnboundLocalError |
访问未初始化的本地变量 |
UnicodeDecodeError |
Unicode 解码时的错误 |
UnicodeEncodeError |
Unicode 编码时错误 |
UnicodeError |
Unicode 相关的错误 |
UnicodeTranslateError |
Unicode 转换时错误 |
| UserWarning | 用户代码生成的警告 |
| ValueError | 传入无效的参数 |
| Warning | 警告的基类 |
WindowsError |
系统调用失败 |
ZeroDivisionError |
除(或取模)零 (所有数据类型) |
with 上下文管理
finally 块由于是否发生异常都会执行,通常我们放释放资源的代码。其实,我们可以通过 with 上下文管理,更方便的实现释放资源的操作。 with 上下文管理的语法结构如下:
1 | with context_expr [ as var]: |
with 上下文管理可以自动管理资源,在 with 代码块执行完毕后自动还原进入该代码之前的 现场或上下文。不论何种原因跳出 with 块,不论是否有异常,总能保证资源正常释放。极 大的简化了工作,在文件操作、网络通信相关的场合非常常用。
With不是取代try…except…finally的,而是作为补充,方便文件管理,网络通信时的开发
1 | with open("d:/bb.txt") as f: |
trackback 模块
1 | #coding=utf-8 |
使用 traceback 将异常信息写入日志文件
1 | import traceback |
自定义异常类
程序开发中,有时候我们也需要自己定义异常类。自定义异常类一般都是运行时异常,通常继承 Exception 或其子类即可。命名一般以 Error、Exception 为后缀。
自定义异常由 raise 语句主动抛出。
1 | classAgeError(Exception): #继承Exception |
if name == ‘main‘:的作用
简单说:
在当前执行的程序下(例如当前程序为test.py),如果导入其他模块(other_test.py),则运行程序时other_test.py的if name == ‘main‘ 语句判断失败,将不会运行下面的方法。
也就是说导入的模块的if name == ‘main‘ 语句下的方法是不会执行的。只会执行当前的if name == ‘main‘ 下的方法。
一个python文件通常有两种使用方法,第一是作为脚本直接执行,第二是 import 到其他的 python 脚本中被调用(模块重用)执行。因此 if name == ‘main’: 的作用就是控制这两种情况执行代码的过程,在 if name == ‘main’: 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行的。举例说明如下:
- 直接执行
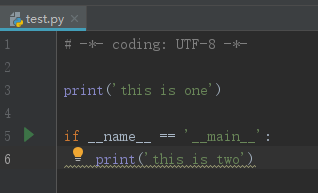
直接执行 test.py,结果如下图,可以成功 print 两行字符串。即,if name==”main“: 语句之前和之后的代码都被执行。

- import 执行
然后在同一文件夹新建名称为 import_test.py 的脚本,输入如下代码:
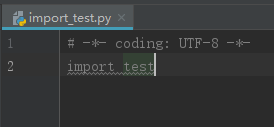
执行 import_test.py 脚本,输出结果如下:

只输出了第一行字符串。即,if name==”main“: 之前的语句被执行,之后的没有被执行。
if name == ‘main‘:的运行原理
每个python模块(python文件,也就是此处的 test.py 和 import_test.py)都包含内置的变量 name,当该模块被直接执行的时候,name 等于文件名(包含后缀 .py );如果该模块 import 到其他模块中,则该模块的 name 等于模块名称(不包含后缀.py)。
而 “main” 始终指当前执行模块的名称(包含后缀.py)。进而当模块被直接执行时,name == ‘main’ 结果为真。
为了进一步说明,我们在 test.py 脚本的 if name==”main“: 之前加入 print(name),即将 name 打印出来。文件内容和结果如下:


可以看出,此时变量name的值为”main“。
再执行 import_test.py,执行结果如下:
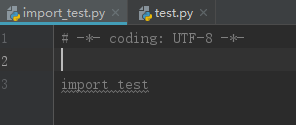

此时,test.py中的name变量值为 test,不满足 name==”main“ 的条件,因此,无法执行其后的代码。