demo
demo.md
Welcome
If you are new here, here are some guideline for you.
If you are Chinese, I am sure you can understand all the blog context.
If you are not familiar Chinese, please add “Translate Chinese Simplified to English” extension to your Chrome Browser. LINK: https://chrome.google.com/webstore/detail/translate-chinese-simplif/aohgcplgnbmgomjjknajcofkchihnbaj/related?hl=en
After add this, please right click the mouth and find the option “Translate Chinese Simplified to English”, and here we go! English Version!
websites
http://www.daihema.com/s/comb/n-%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&f-pdf 搜各种教材资料
https://www.dalipan.com/ 大力盘,也是搜索资源的,各种网盘资料
非常全面的人工智能
听说你想了解人工智能?这篇文章教你从零基础成为深度学习高手

汽车 话题的优秀回答者
关注他
编辑推荐
2,973 人赞同了该文章
本文共9876字,阅读约需14分钟。
近期在公司内部做了一个关于人工智能/深度学习相关的主题分享讲座,为了准备这个演讲,我花了100个小时左右,接下来就把精心准备的内容分享给大家。
有一个好消息是,考虑文章比较长和文字本身表达的局限性,同时为了解答大家的疑问,我近期会完全免费开一个视频直播,具体内容如下。
\1. 深度学习入门到晋级
\2. 深度学习模型解析和代码实现展示
\3. 答疑环节
————-分割线—————
好,内容正式开始。
一提到人工智能和深度学习,很多人觉得比较难,其实那只是因为没有遇到能够讲的清楚的人而已。
很多人喜欢把简单的事情说得玄乎,以显示自己很厉害,但其实真正厉害的人,是能够把复杂的事情讲解的很深入浅出、通俗易懂的,这也是我一直努力的方向。
看这篇文章的读者,估计大多数可能之前没有深入了解过深度学习,这么说来,我有幸成为各位在深度学习方面的启蒙老师了(笑)。
分享的内容分四部分,分别是入门、基础、进阶和发展趋势。
深度学习简单入门
2016年3月份,AlphaGo以4:1战胜韩国围棋手李世石,一举震惊了世界。
人工智能一下就引爆了整个世界。有种趋势就是,不谈人工智能,就落伍了。
以前资本圈融资都谈的是“互联网+”,现在都在谈“AI+”了。
有人说,马上人工智能时代就要来了,甚至有人宣扬人工智能威胁论。
那么,当我们谈论人工智能的时候,我们究竟在谈论什么呢?

我们先来讨论下“人工智能”的定义。
什么叫做智能呢?所谓智能,其实就是对人某些高级功能的模拟,让计算机去完成一些以前只有人才能完成的工作,比如思考、决策、解决问题等等。
比如以前只有人可以进行数学计算,而现在计算机也可以进行计算,而且算的比人还准,还快,我们说计算机有一点智能了。
人工智能的发展经历了好几个发展阶段,从最开始的简单的逻辑推理,到中期的基于规则(Rule-based)的专家系统,这些都已经有一定的的智能了,但距离我们想象的人工智能还有一大段距离。直到机器学习诞生以后,人工智能界感觉终于找到了感觉。基于机器学习的图像识别和语音识别在某些垂直领域达到了跟人相媲美的程度。人工智能终于能够达到一定的高度了。
当前机器学习的应用场景非常普遍,比如图像识别、语音识别,中英文翻译,数据挖掘等,未来也会慢慢融入到各行各业。

虽然都是机器学习,但是背后的训练方法和模型是完全不同的。
根据训练的方法不同,机器学习算法可以大致分类为监督学习、无监督学习和强化学习三种。

监督学习,就是训练数据是有标签的,也就是每个数据都是标注过的,是有正确答案的。训练的时候会告诉模型什么是对的,什么的错的,然后找到输入和输出之间正确的映射关系,比如物体种类的图像识别,识别一张图片内容是只狗,还是棵树。
非监督学习,就是训练数据没有标签的,只有部分特征。模型自己分析数据的特征,找到数据别后隐含的架构关系,比如说自己对数据进行学习分类等等,常见的算法有聚类算法,给你一堆数据,将这数据分为几类。比如在银行的数据库中,给你所有客户的消费记录,让你挑选出哪些可以升级成VIP客户,这就是聚类算法。
还有一种是强化学习,目标是建立环境到行为之间的最佳映射。强化学习的训练是不需要数据的,你告诉他规则或者给他明确一个环境,让模型自己通过不断地尝试,自己根据结果来自己摸索。
Deep Mind的AlphaGo Zero就是通过强化学习训练的,号称花了3天的训练时间就能100:0打败AlphaGo。
比较适合强化学习的一般是环境到行为之间的结果规则比较明确,或者环境比较单一、不太容易受噪音干扰等等,比如下围棋的输赢等等,还可以模拟直升机起降、双足机器人行走等等。
我们今天讨论的就是基于监督学习在图像识别领域的应用。
接下来我们再看下人工智能的历史。
虽说我们感觉人工智能最近几年才开始火起来,但是这个概念一点也不新鲜。
起源于上世纪五、六十年代就提出人工智能的概念了,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果,当时的人们对此非常乐观,号称要在10年内解决所有的问题。但是,单层感知机有一个严重得不能再严重的问题,即它对稍复杂一些的函数都无能为力(比如最为典型的“异或”逻辑),连异或都不能拟合。当时有一个专家叫明斯基,号称人工智能之父,在一次行业大会上公开承认,人工智能连一些基本的逻辑运算(比如异或运算)都无能为力,于是政府所有的资助全部都停掉了,于是进入人工智能的第一个冬天。
随着数学的发展,这个缺点直到上世纪八十年代才发明了多层感知机克服,同时也提出了梯度下降、误差反向传播(BP)算法等当前深度学习中非常基础的算法。之前被人诟病的问题已经被解决了,希望的小火苗又重新点燃了,于是人工智能开始再次兴起。
但是没过多久大家发现了,虽然理论模型是完善了,但是并没有实际用途,还不能解决实际问题,于是又冷下去了,人工智能的第二个冬天降临。
直到2012年开始第三次兴起,也就是最近几年人工智能的热潮。
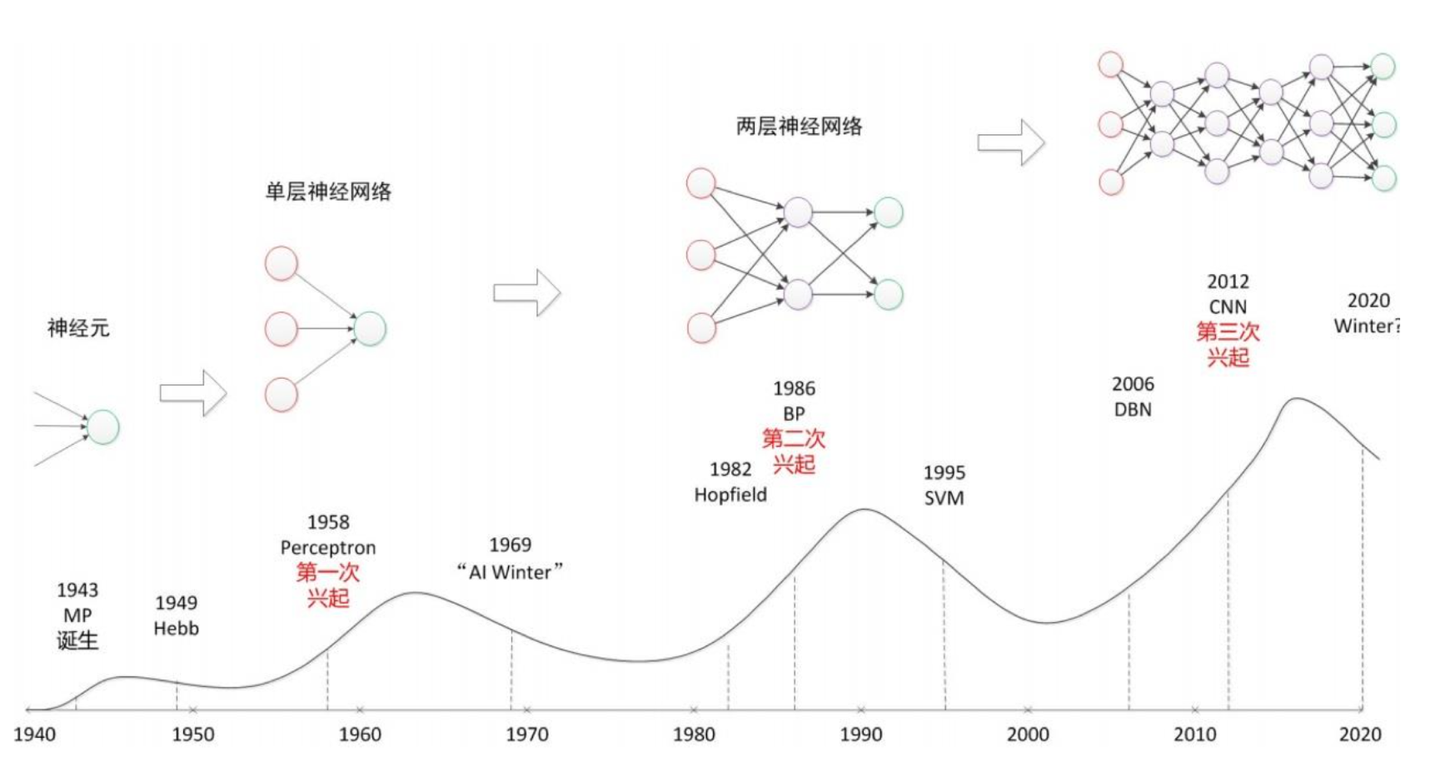
下面我们就来第三次热潮是如何兴起的。
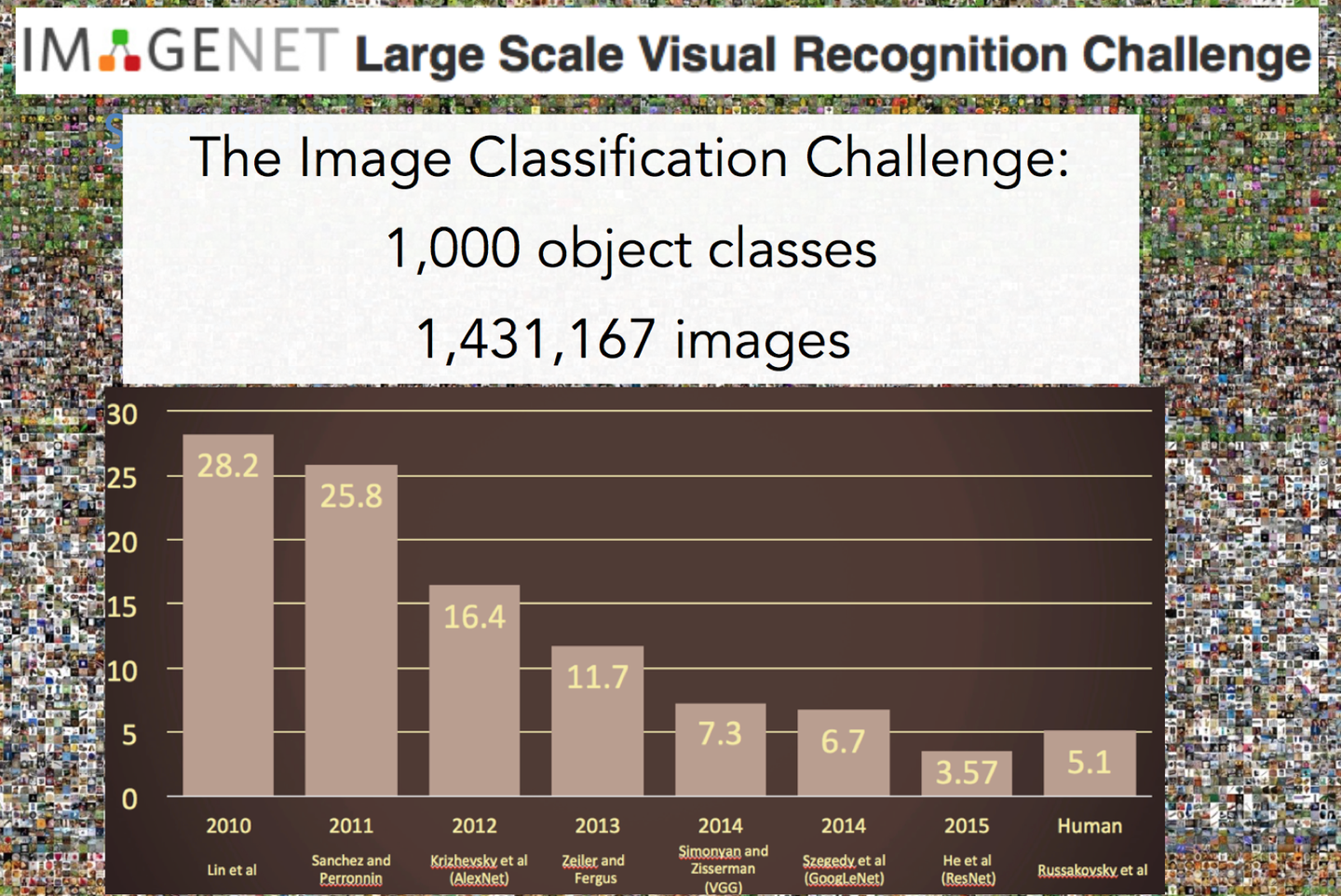
在这之前,我们先介绍一个比赛。这个比赛是一项图像识别的挑战赛,给你大量图片去做图像识别,比赛看谁的识别错误低。在2012年之前,错误率降低到30%以后,再往下降就很难了,每年只能下降个2,3个百分点。
直到2012年,有一个哥们叫Alex,这哥们在寝室用GPU死磕了一个卷积神经网络的模型,将识别错误率从26%下降到了16%,下降了10%左右,一举震惊了整个人工智能界,当之无愧的获得了当年的冠军。
从此之后,卷积神经网络一炮而红。之后每年挑战赛的冠军,胜者都是利用卷积神经网络来训练的。2015年,挑战赛的错误率已经降低到3.5%附近,而在同样的图像识别的任务,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
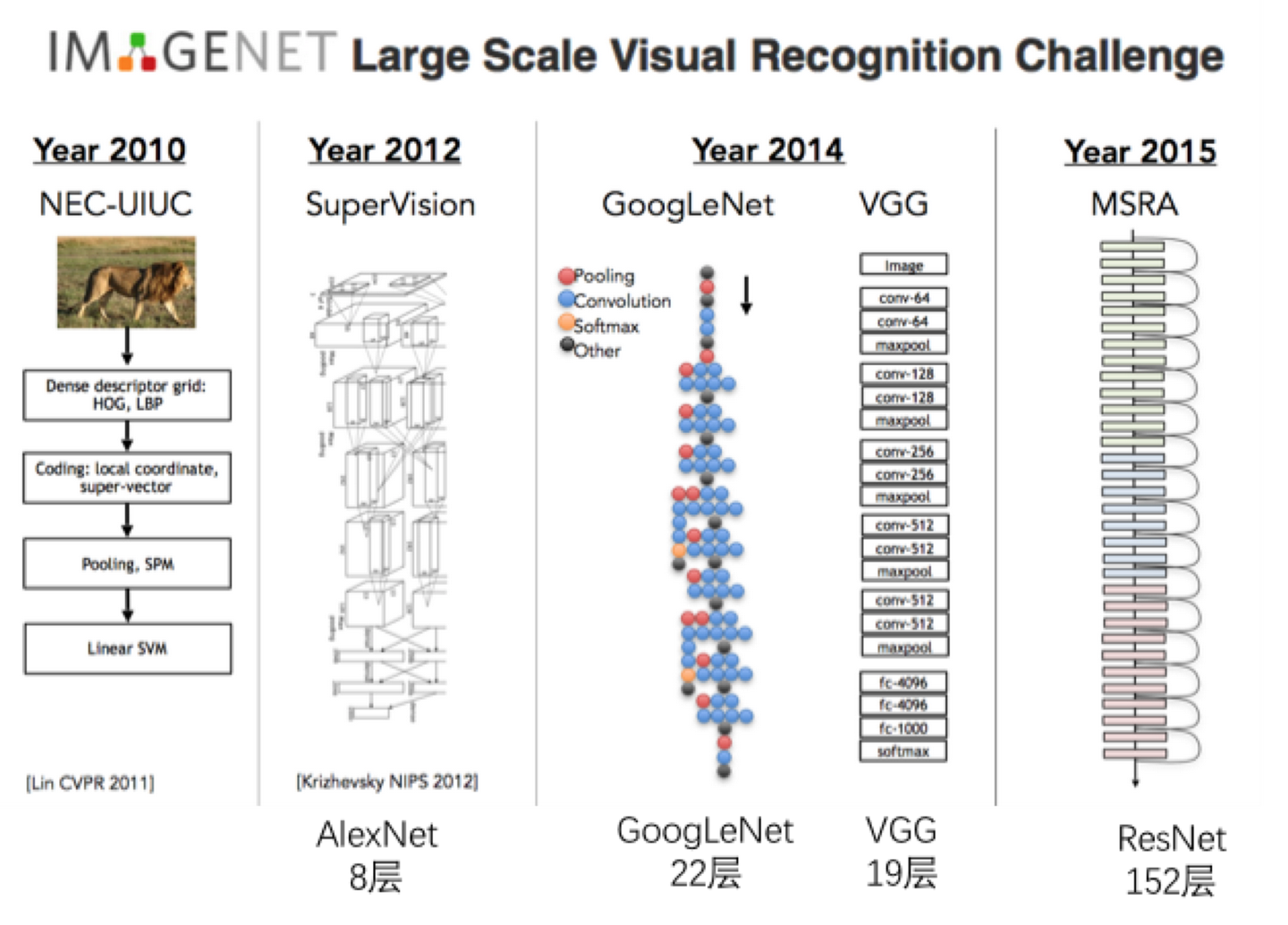
下图是最近几年比较有代表性的模型的架构。
大家可以看出来,深度学习的模型的发展规律,深,更深。没有最深,只有更深。
那么Alex的卷积神经网络这么厉害,是因为这个哥们是个学术大牛,有什么独创性的学术研究成果么?
其实并不是。
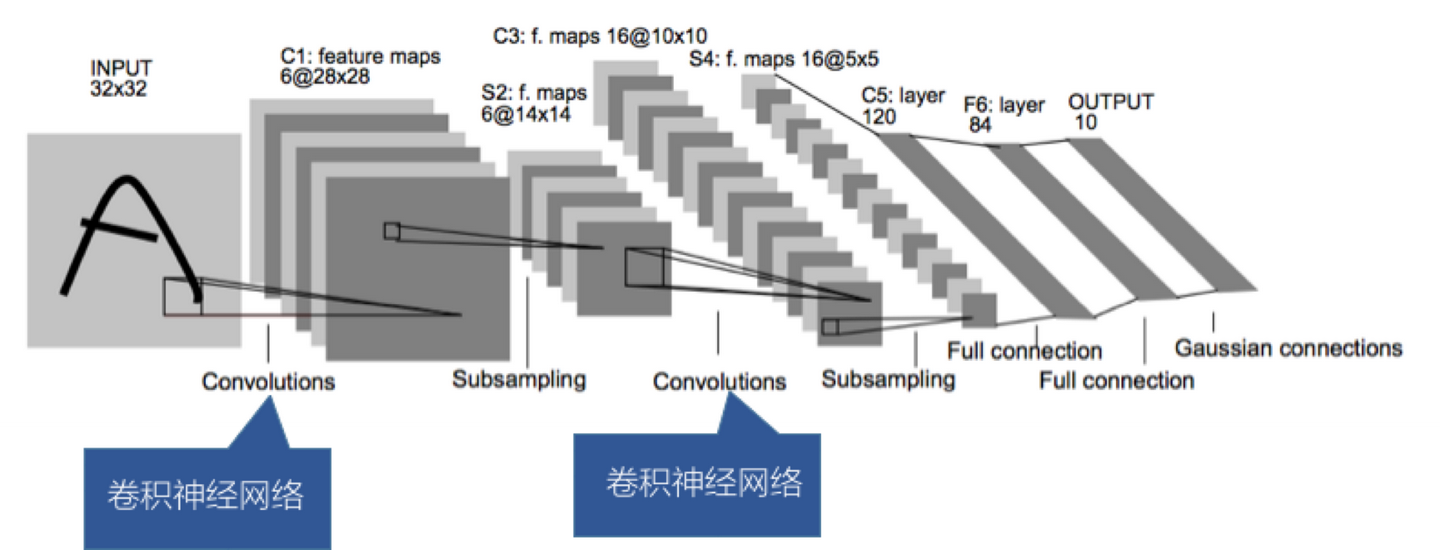
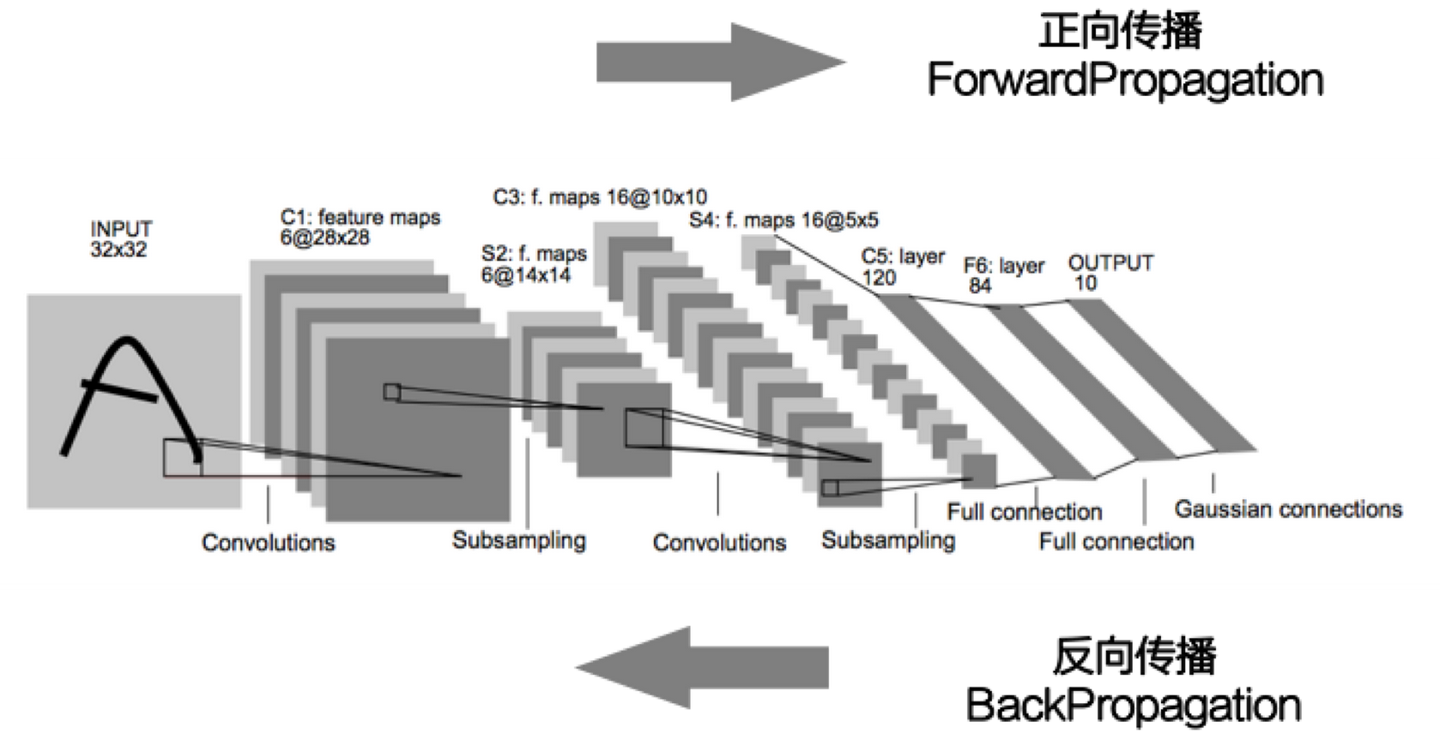
他所采用的模型是1998年Yann Lecun就提出了这个模型,当时Yann Lecun把这个模型应用在识别手写邮编数字的识别上,取得了很好的效果,他搭建的网络,命名为Lenet。这个人的名字——Yann Lecun,大家一定要记住,因为我们后面的内容将会以Lenet作为范本来讲解。
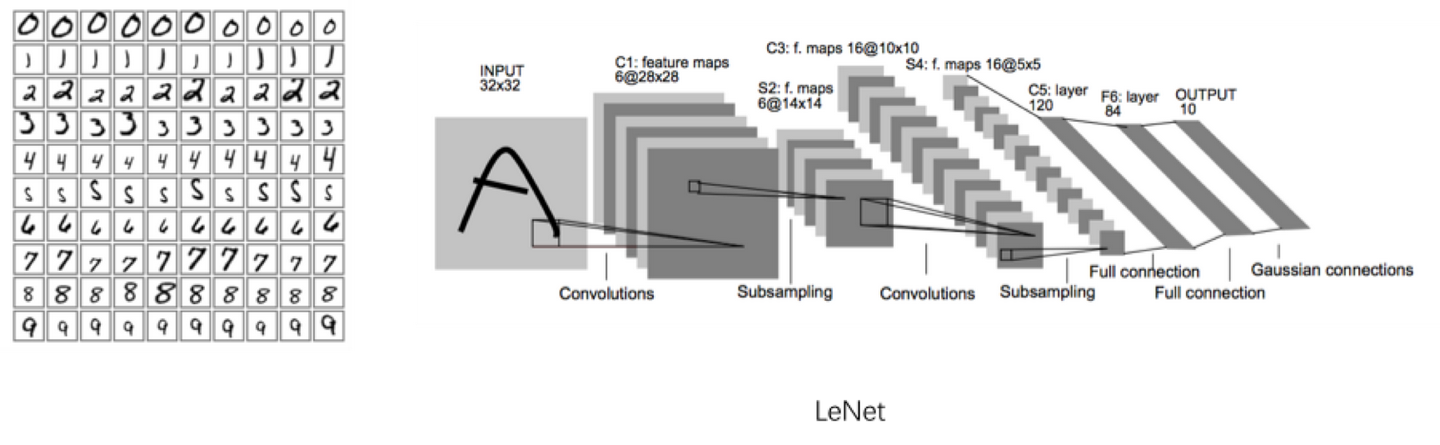
这个模型是1998年提出来的,可为什么时隔这么多年才开始火起来呢?
人工智能突然爆发背后深层次的原因是什么?我总结了一下,背后的原因主要有三个:

1.算法的成熟,尤其是随机梯度下降的方法的优化,以及一些能够有效防止过拟合的算法的提出,至于什么是随机梯度下降和过拟合,后面我们会详细讲到
2.数据获取,互联网的爆发,尤其是移动互联网和社交网络的普及,可以比较容易的获取大量的互联网资源,尤其是图片和视频资源,因为做深度学习训练的时候需要大量的数据。
3.计算能力的提升,因为要训练的数据量很大(都是百万级以上的数据),而且训练的参数也很大(有的比较深的模型有几百万甚至上千万个的参数需要同时优化),而多亏了摩尔定律,能够以较低的价格获取强大的运算能力,也多亏了Nvida,开发了GPU这个神器,可以大幅降低训练时间。
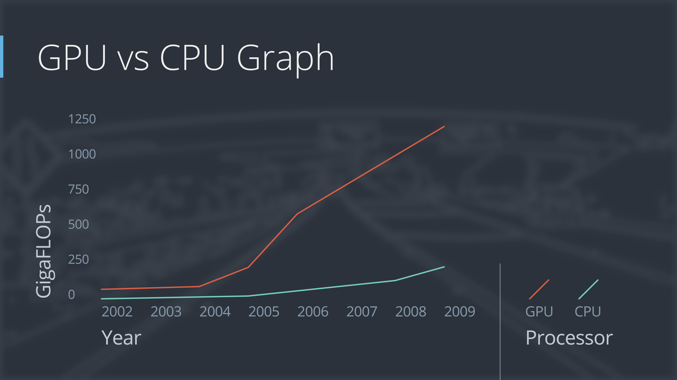
GPU的运算速度是CPU的5-10倍左右,同样的模型需要训练,如果用CPU训练需要一个礼拜的话,那使用GPU,只需要一天时间就可以了。
截止到目前,我们汇总下我们的学习内容,我们了解了人工智能的简单介绍,大致了解了人工智能的算法分类以及发展历史。
深度学习基础知识
接下来我们了解一下基础知识。
我们上面也提到了,我们这次主要以卷积神经网络在图像识别领域的应用来介绍深度学习的。
卷积神经网络,这个词听起来非常深奥。
但其实没什么复杂的,我们可以分开成两个词来理解,卷积和神经网络。
先看下卷积。
卷积时数学的定义,在数学里是有明确的公式定义的。
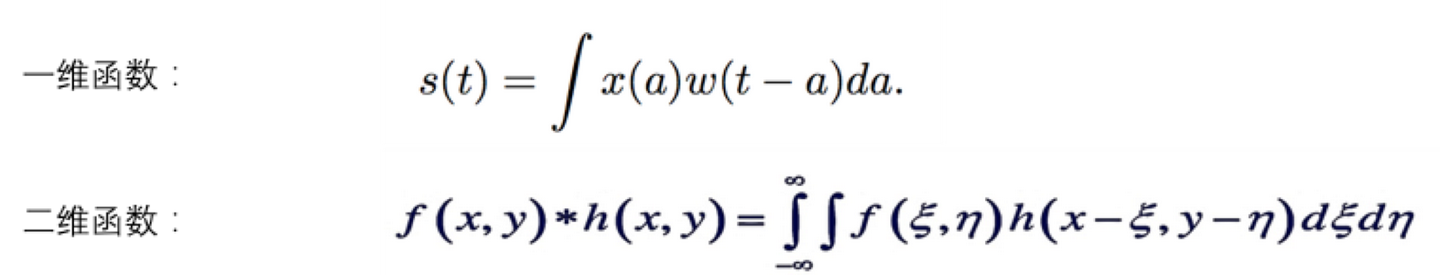
是不是觉得公式太抽象,看不明白?没关系,我们举个栗子就明白了。

还是以图像识别为例,我们看到的图像其实是由一个个像素点构成的。
一般彩色图像的是RGB格式的,也就是每个像素点的颜色,都是有RGB(红绿蓝三原色混合而成的),是三个值综合的表现。
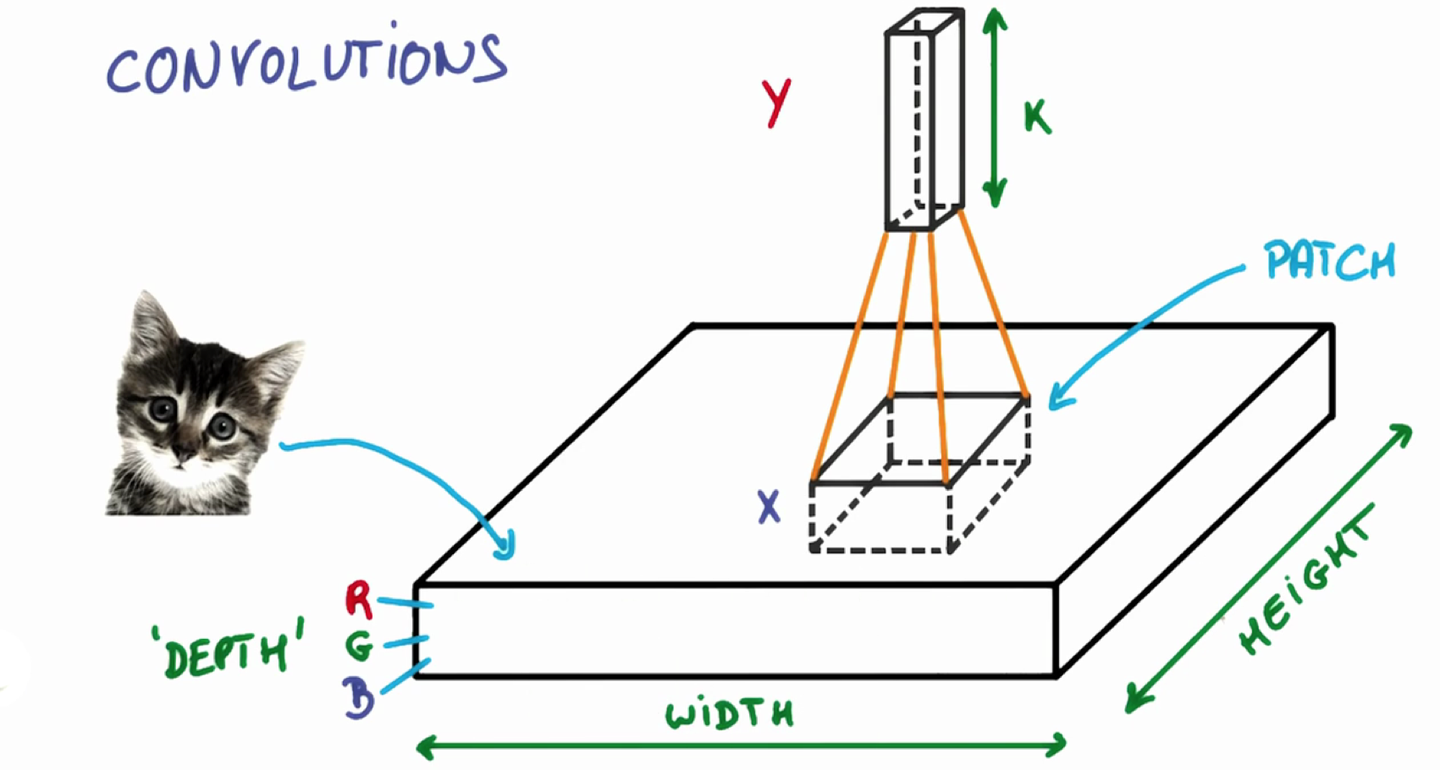
假设f函数为5x5(对应到图片上即为5x5像素)为例,h函数为3x3的函数,大家可以理解为为一个手电筒(也就是筛选器),依次扫过这个5x5的区间。在照过一个区域,就像对应区域里的值就和框里的数据去做运算。最终输出为我们的输出图。
手电筒本身是一个函数,在3x3的区域内,他在每个位置都有参数,它的参数和对应到图片上相应位置的数字,先相乘,然后再把相乘的数字相加的结果输出,依次按照这些去把整个图片全部筛选一遍,就是我们所说的卷积运算了。
还是比较抽象,没关系,看下面这个图片就清楚了。
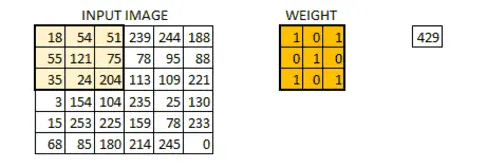
那我们为什么要做卷积呢?我们其实就是建立一个输入和输出的函数,图像识别的目的就是把输入的信息(像素点信息)对应到我们输出结果(识别类别)上去,所以是逐层提取有用特征,去除无用信息的过程。
比如下图所示,第一层可以识别一些边缘信息,后面逐层抽象,汇总到最后,就可以输出我们想要的结果,也就是我们的识别结果。
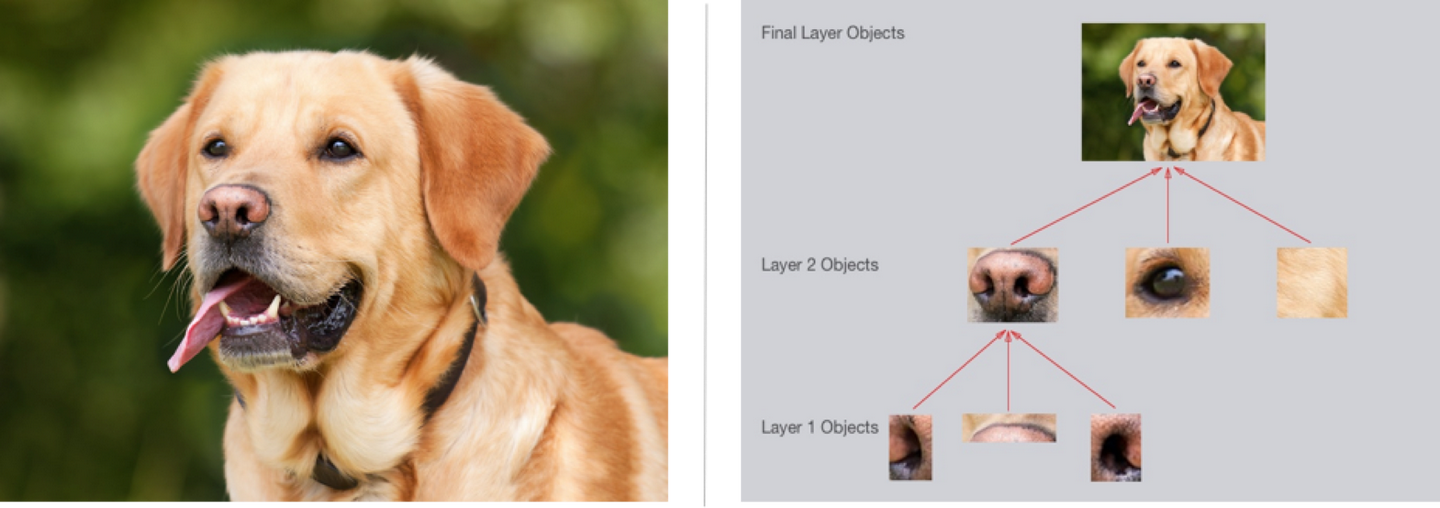
虽然我们知道特征是逐层抽象提取的,但是不幸的是,我们并不知道那一层是具体做什么的,也就不知道那个层数具体是什么意思。
也就是说,其实深度学习网络对于我们而言,是个黑盒子,我们只能通过他的输出来判断其好坏,而不能直接去调整某个参数。
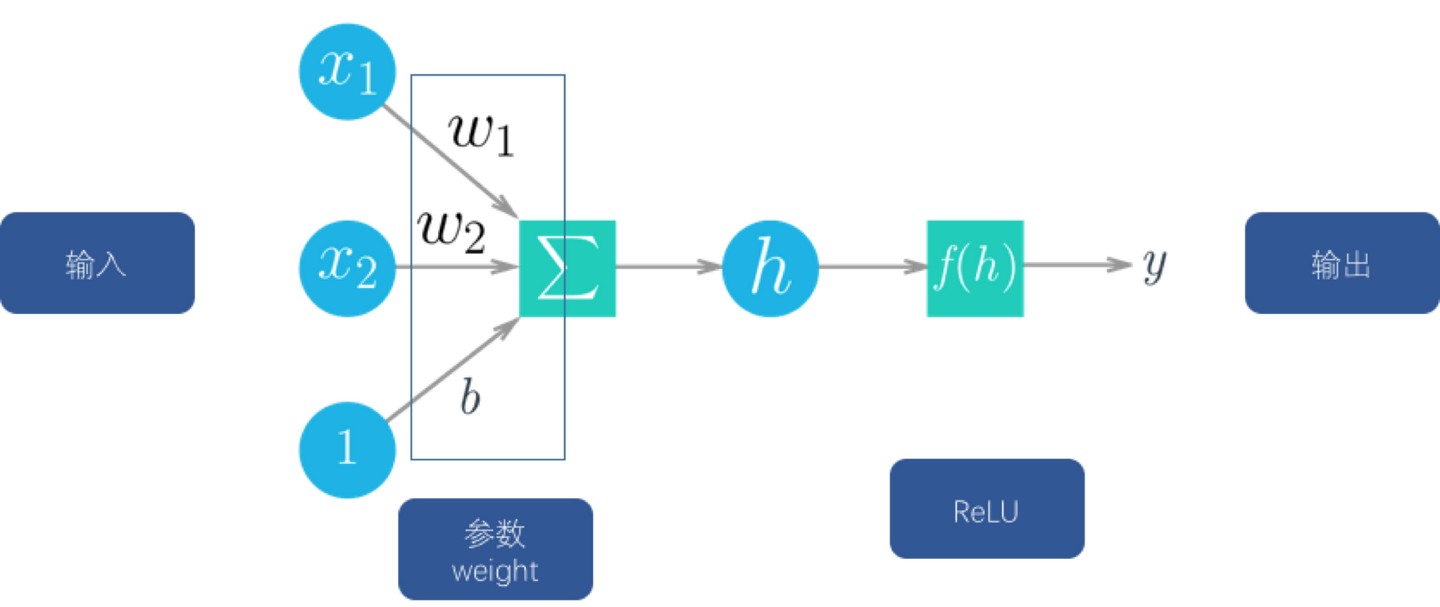
那么,什么是神经网络呢?其实这个模型来自于心理学和神经学,人工智能的专家借鉴了这个结构。
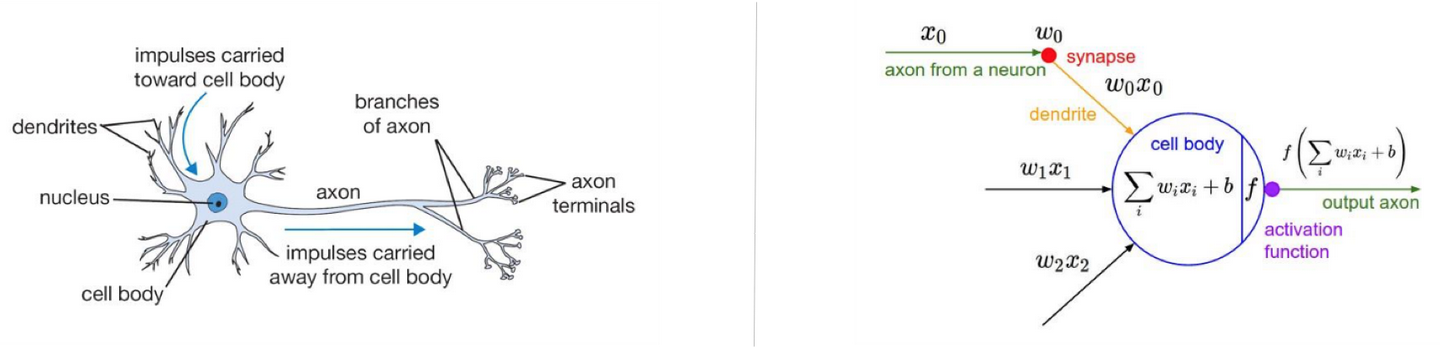
左侧为神经元,神经元接收外界的输入刺激或者其他神经元的传递过来的信号,经过处理,传递给外界或者给其他神经元。
右侧为我们根据神经元的生物学特征抽象出来的数学模型,其中x是输入,包括一开始数据来源(外部刺激)的输入,也包括其他节点(神经元)的输入。
w为参数(weight),每个节点还有一个b,这个b其实是一个偏置。
大家在学习新东西的时候,凡事多问个为什么?只有知道背后的原因了,这样你才能理解的更深刻。有句话说得好,还有什么比带着问题学习更有效率的学习方法呢?
为什么要加这个b呢?大家想想看,如果没有b的话,当输入x为0的时候,输出全部为0,这是我们不想看到的。所以要加上这个b,引入更多的参数,带来更大的优化空间。
大家看一下,目前为止,这个神经元里的函数(对输入信号的处理)都还是线性的,也就是说输出与输入是线性相关的,但是根据神经元的生物学研究,发现其接受到的刺激与输入并不是线性相关的,也为了能够表征一些非线性函数,所以必须要再引入一个函数,也就是下面我们要讲的激活函数(activation function)。
为什么需要激活函数?因为需要引入一些非线性的特性在里面。
常见的激活函数有这些。
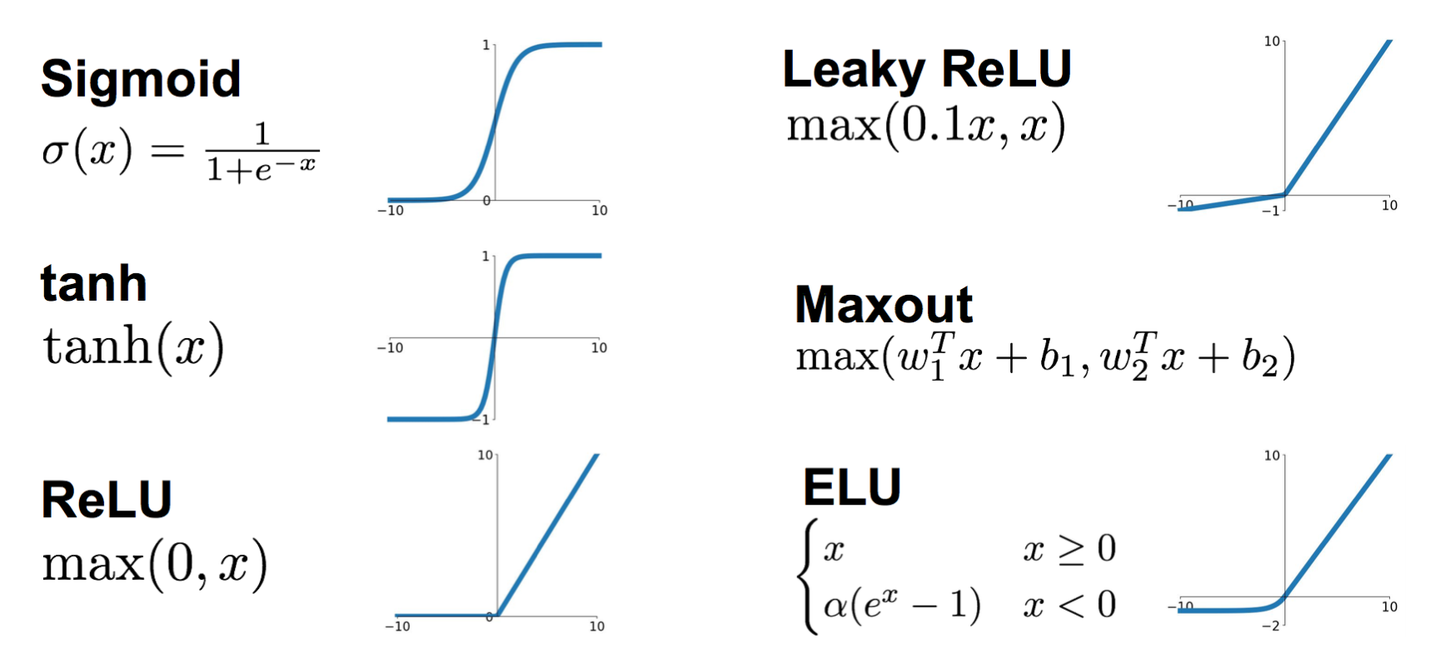
以前是sigmoid比较常见,但是现在ReLU用的比较多一些。
就类似于下图这样,在节点经过线性运算后,经过非线性的ReLU,然后进入下一层的下一个节点。中间的w和b,就是我们卷积神经网络的参数,也是我们模型中需要训练的对象。
大家看LeNet模型中,就是在输入数据多次进行卷积神经网络的处理。
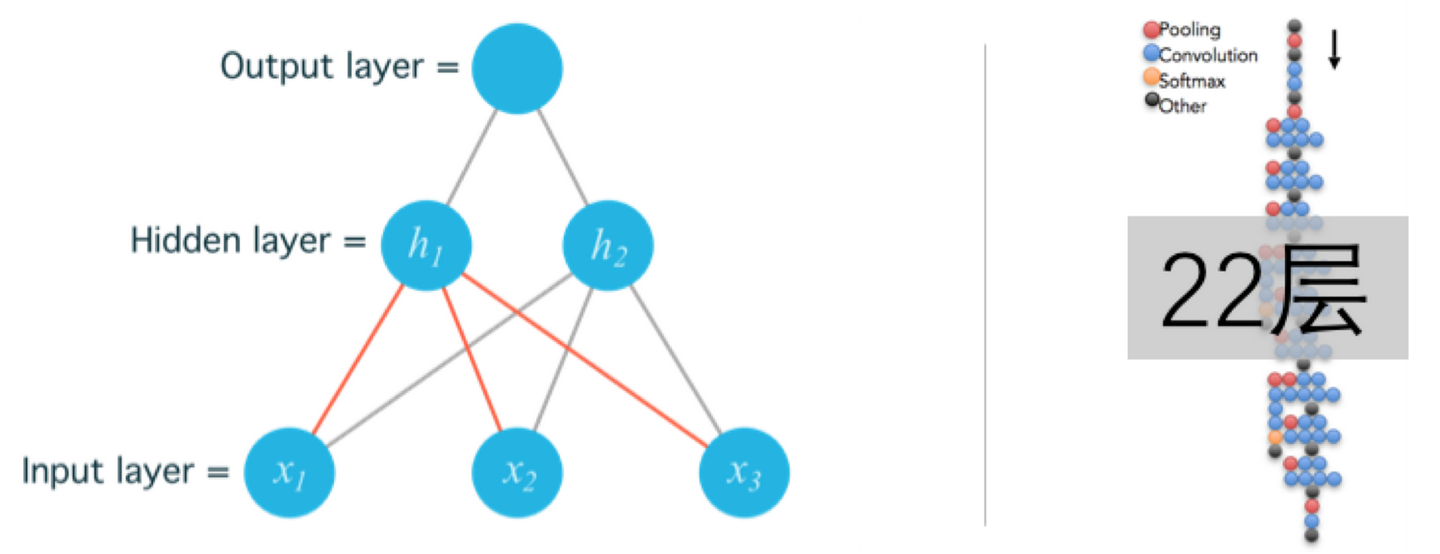
对于模型而已,我们习惯把输入的数据叫做输入层,中间的网络叫做隐藏层,输出的结果叫做输出层。中间层数越多,模型越复杂,所需要训练的参数也就越多。
所谓的deep learning中的deep,指的就是中间层的层数,右图中GoogLenet有22层。
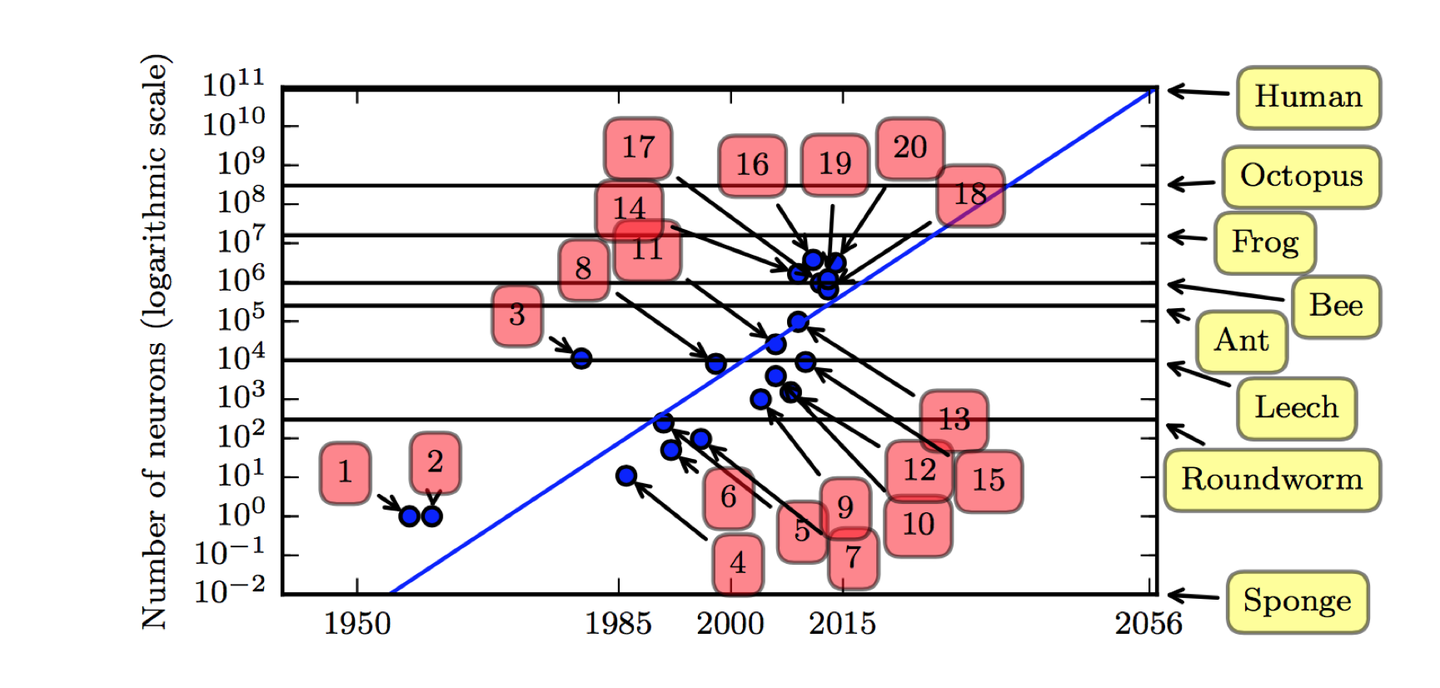
一般说来,模型越复杂,所能实现的功能也越强大,所能达到的精度也越高,目前最深的模型大概有10的7次方个神经元,其神经元比相对原始的脊椎动物如青蛙的神经系统还要小。
自从引入隐藏单元,人工神经网络的大小大约每 2.4 年翻一倍,按照现在的发展速度,大概要到2050年左右才能达到人类大脑的神经元数量的规模。
损失函数
怎么判断一个模型训练的好坏呢?我们需要一个评价指标(也就是KPI考核指标),也就是损失函数。
我们最初的目标是什么?是建立输入输出的映射关系。
比如我们的目标是判断一张图片上是只猫,还是一棵树。那这张图片上所有的像素点就是输入,而判断结果就是输出。
那怎么表征这个模型的好坏呢?很简单,大家应该很容易想到,就是把模型输出的答案和正确答案做一下比对,看一下相差多少。
我们一般用下面这个公式(平均平方误差,即MSE)来评估我们的模型好坏。
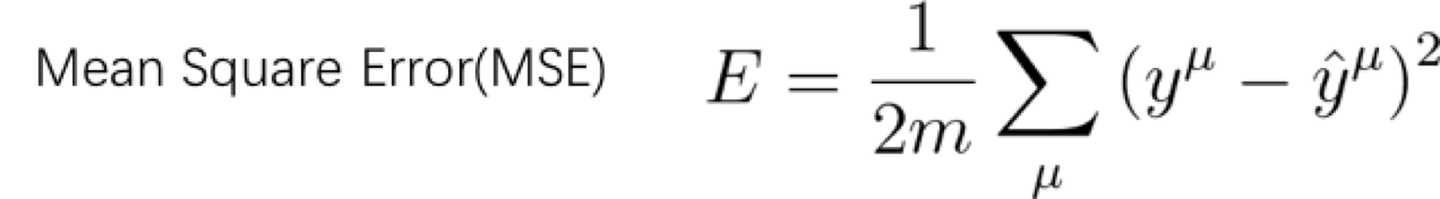
我们就是通过对比输出结果与预期结果的差异,其中带帽子的yu就是预期的结果(也就是标签值,即是真值),而前面的不带帽子的yu就是实际的输出结果。当训练结果非常好的时候,比如说是全对的时候,平均误差就是0。当训练结果非常差的时候,比如说全错的时候,误差即为1.
于是我们知道了,这个E越小越好,最好变成0.
大家注意下,这个求和的标识,表示是所有的数据的和,而不是一个的数值。我们常说大数据来训练模型,其实这就是大数据。我们训练的时候需要上百万张的图片,最终得出来的误差,就是这里,然后再除以数量,取平均值。
那怎么去降低这个误差呢?要回答这个问题,就涉及到卷积神经网络的核心思想了,也就是反向传播。
反向传播/梯度下降
既然讲到机器学习,那当然是让机器自己去通过数据去学习,那机器是如何进行自学习的呢?下面就要敲黑板,划重点了,因为这就是深度学习的重中之重了,也就是机器学习的核心了,理解了这个概念,基本上就理解了一多半了。
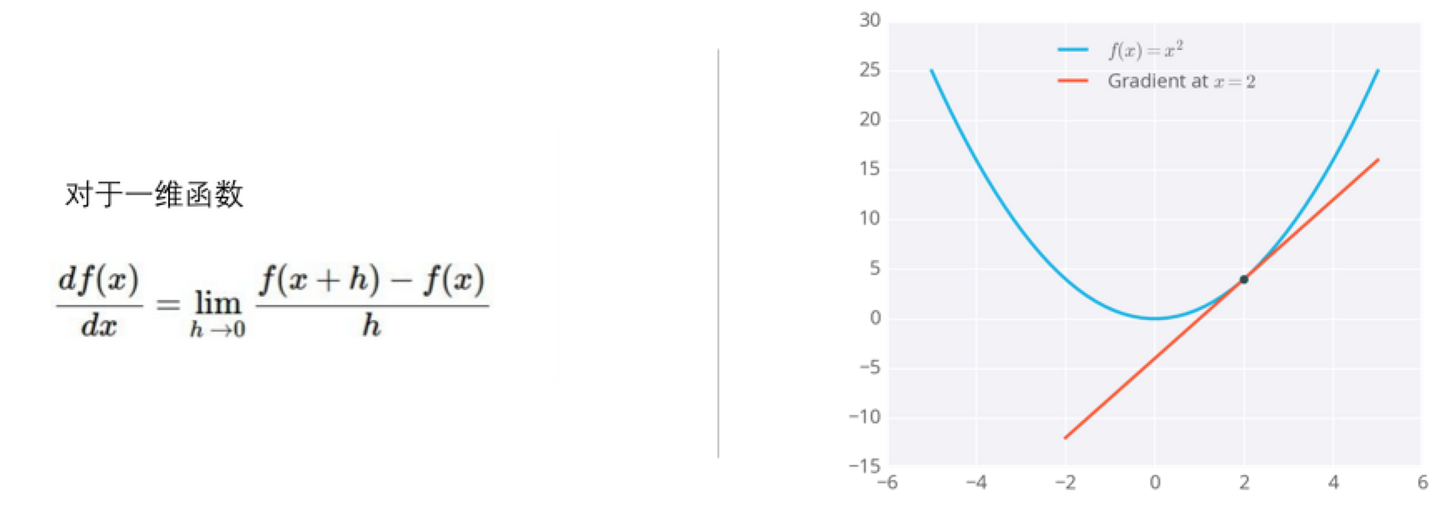
这个概念就是反向传播。听名字比较玄乎,其实这个概念大家在高等数学里都接触过这个概念了——梯度,其实也就是求导。
对于一维函数而言,函数梯度下降的方向就是导数的反方向。
对于二维函数而言,就是把误差对每个变量求偏导,偏导的反方向即为梯度下降的方向。
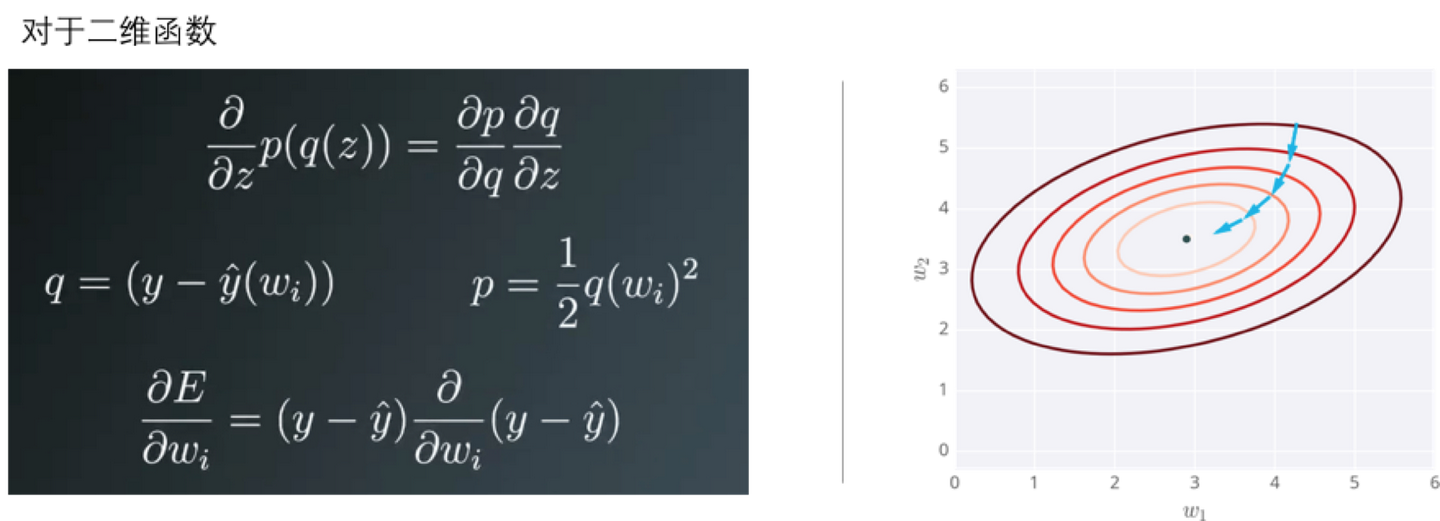
说起来有点抽象,我们举个实例来说明一下。
下面是我们的参数和损失函数的值。

我们先对第一个参数加一个极小值,算出新的损失函数。

然后用损失函数的变化去除这个极小值,就是这个参数的梯度了。

同样我们可以使用同样的方法去求得其他参数的梯度。


只要找到梯度下降的方向,按照方向去优化这些参数就好了。这个概念就是梯度下降。
但是我们知道,我们要训练的参数非常多,数据量也非常大,经常是百万、千万量级的,如果每次都把全部训练数据都重新计算一遍,计算损失函数,然后再反向传播,计算梯度,这样下去,模型的误差优化的非常非常慢。
那有没有更快的方法呢?
当然有了。
这些参数(weights),数量非常多,大概有上百万个,为了保证能够更好、更快的计算,节省算力,一般选用随机梯度下降方法,随机抽取一定数量(即为批量,batch)的样本,去计算梯度值,一般选择32/64/128。
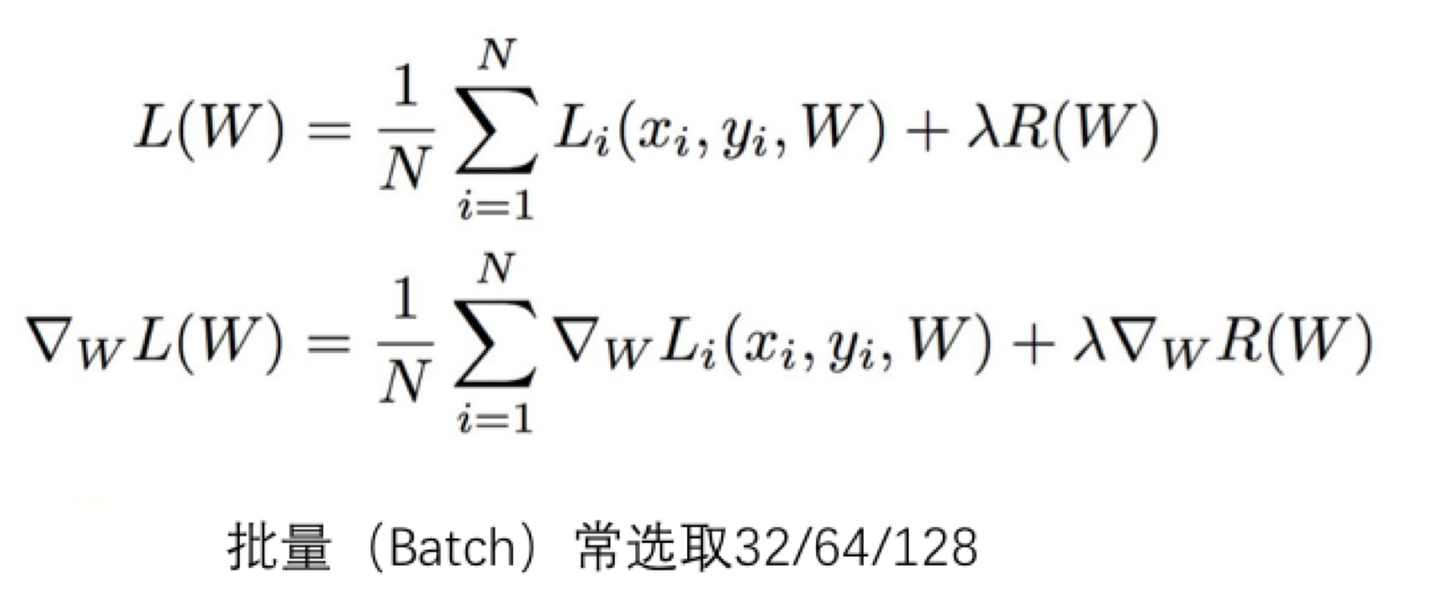
这个方法就是随机梯度下降,这个批量(batch)这也是大家经常要调的参数。
我们可以这样理解随机梯度下降,其核心思想是,梯度是期望。期望可使用小规模的样本近似估计。具体而言,在算法的每一步,我们从训练集中均匀抽出小批量样本来代替全部数据的梯度,因为其梯度期望是一致的。
值得一提是:这些batch中的样本,必须是随机抽取的,否则其期望就准确了。选的批量(batch)的值越小,进行一次参数优化的计算量越小,就越快,但是其随机性会比较大一些,如果选取的批量值比较大,则计算会稍微慢一些,但是随机性会小一些,这是我们需要权衡的。
前向计算一次,反向反馈一下,更新一下参数,叫做一个Epoch.
Epoch的次数也是个超参数,也是需要搭建模型的时候可以调整的参数。
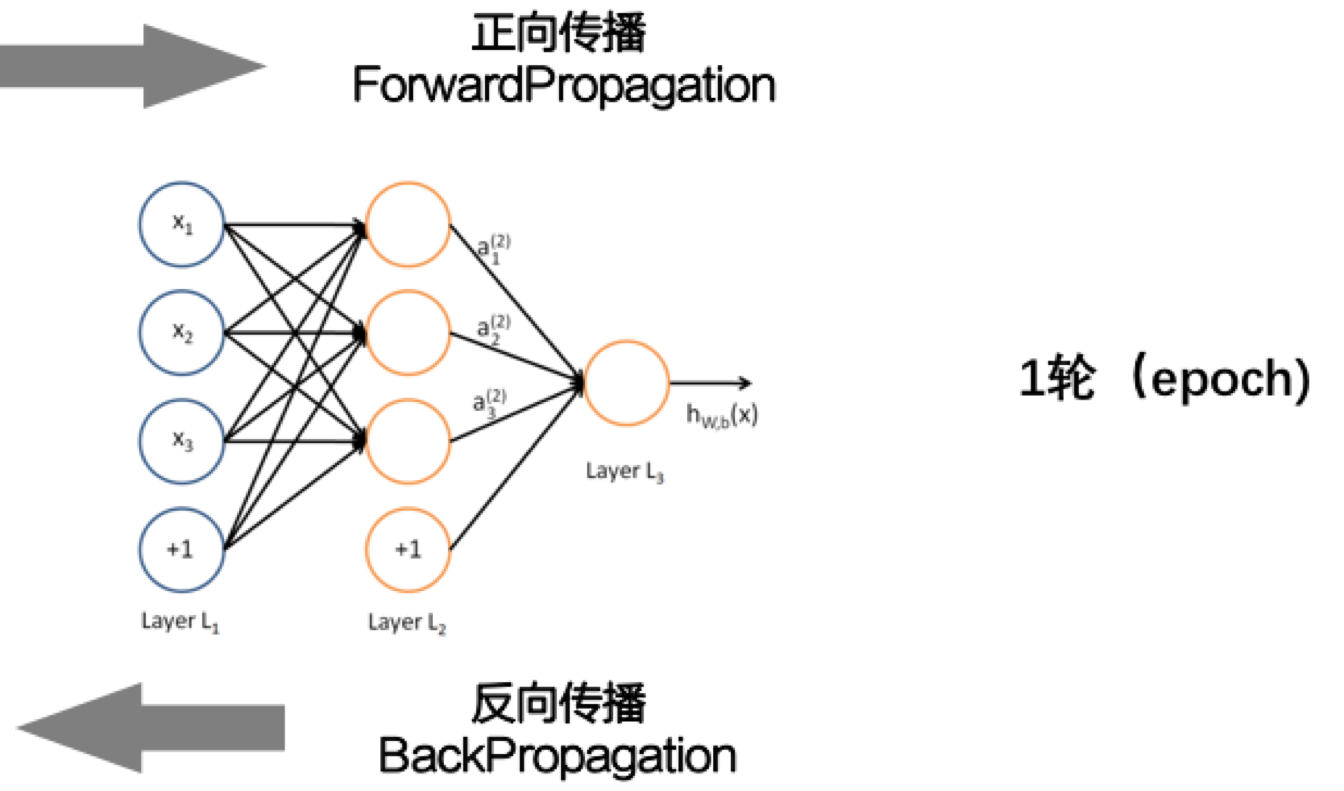
在整个模型中也是类似的。
简单总结下,截止到目前,我们已经了解了一些深度学习的基本概念,比如什么是卷积神经网络,了解了反向传播的传播的概念,如何梯度下降的方法去优化误差。
基本上深度学习是什么回事,大家已经知道了,但是深度学习还需要注意一些细节。有句话说的好,细节就是魔鬼,细节处理的好坏很大程度上决定了你是一个高手,还是一个菜鸟。
深度学习之高手进阶
我们在进行深度学习的时候一般会按照这4个步骤进行。
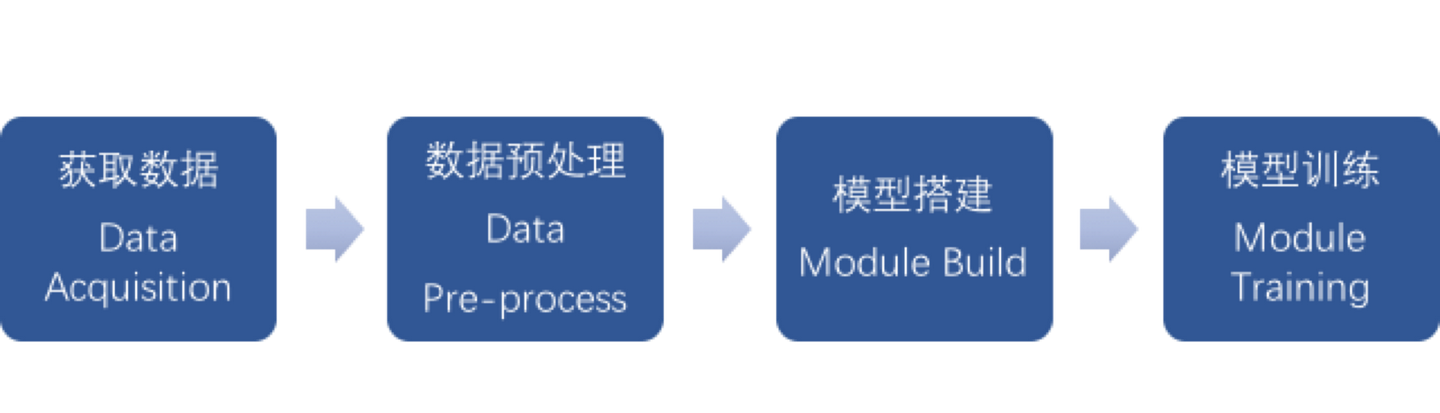
获取数据
很大程度上,数据的多少决定模型所能达到的精度。再好的模型,没有足够数据,也是白瞎。
对于监督学习而言,需要大量标定的数据。
数据的获取是有成本的,尤其是我们需要的数据都是百万、千万量级的,成本非常高。亚马逊有个专门发布标定任务的平台,叫做Amazon Mechanical Turk.
很多大的数据,比如IMAGENET就是在这上面做label的。
Amazon从中抽取20%的费用,也就是说,需求方发布100美元的任务,得多交20美元给Amazon,躺着也挣钱。
由于数据的获取是有成本的,而且成本很高的。
所以我们需要以尽量低的价格去获得更多的数据,所以,在已经获得数据基础上,仅仅通过软件处理去扩展数据,就是非常重要的,常见的数据扩展的方法见下图。

数据预处理-归一化
为了更好的计算数据,避免出现太大或者太小的数据,从而出现计算溢出或者精度失真,一般在开始做数据处理之前,需要进行归一化处理,就是将像素保持在合理的范围内,如[0,1]或者[-1,1]。
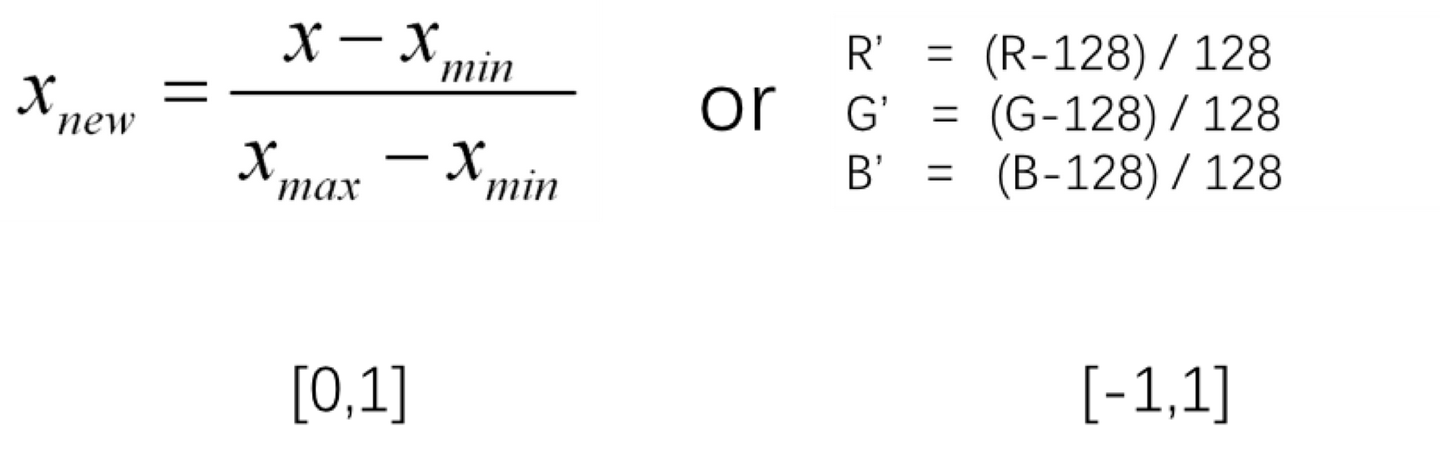
模型搭建
除了上面提到的卷积神经网络之外,我们在搭建模型的时候,还需要一些其他层,最常见的是输出控制。
全连接层Fully-connected
全连接层,其字面意思就是将每个输入值和每个输出值都连接起来,全连接层的目的其实就是控制输出数量。
比如我们最终分类是有10类,那我们需要把输出控制为10个,那就需要一个全连接层来链接输出层。
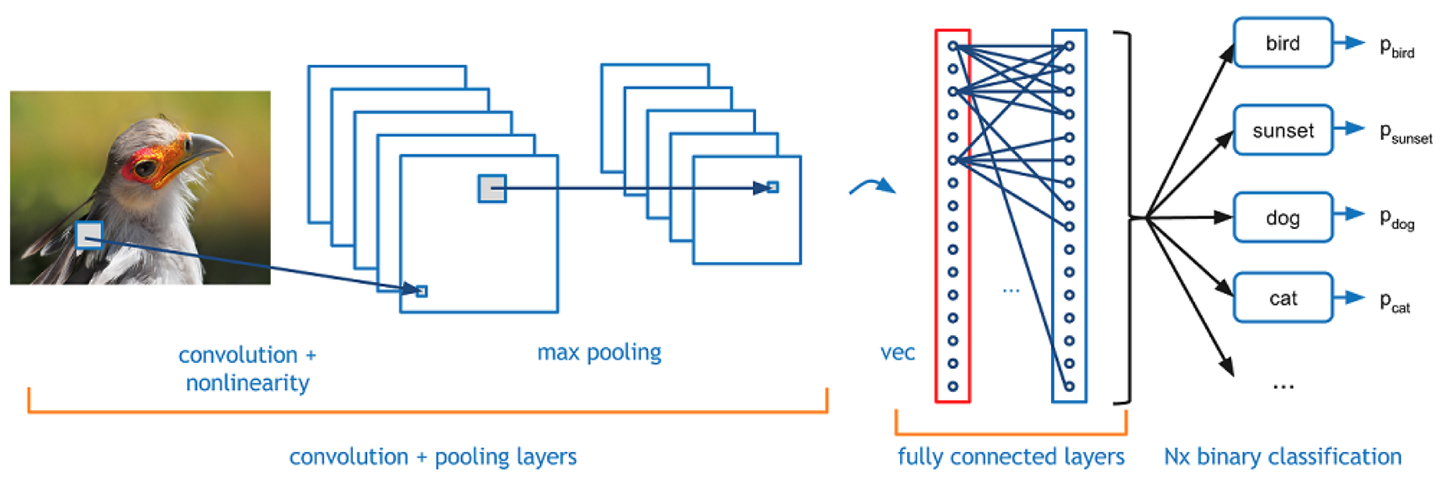
softmax
我们用数值来表征其可能性大小,数值越大,其可能性越大,有的值可能很大,有的值可能很小,是负的。
怎么用概率来表征其可能性呢?总不能加起来一除吧,但是有负数怎么办呢?全连接之后,我们每个类别得到一个值,那怎么转化表征其可能性的概率呢?我们一般通过softmax来转化。
softmax的目的就是把数值转化给每个标签的概率,就是将最终各个值的得分,转化成各个输出值的概率。
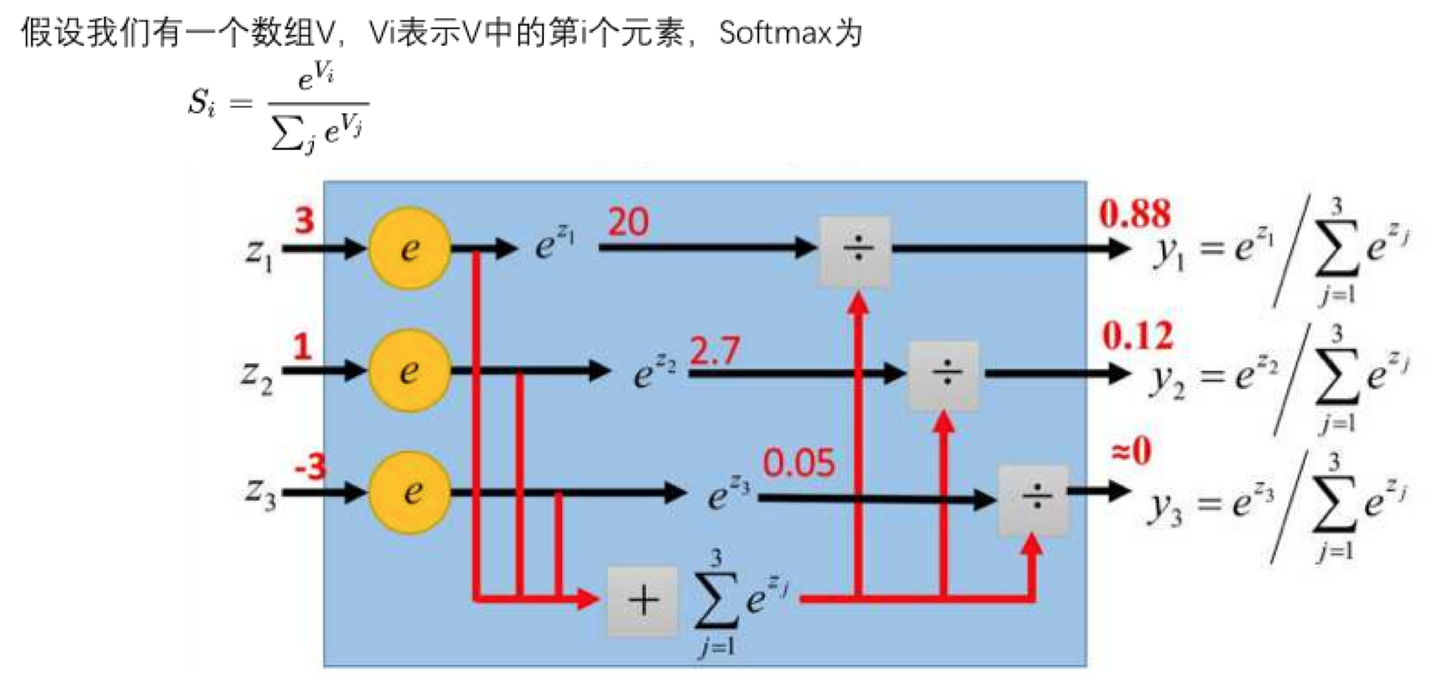
独热编码 One-Hot Encoding
独热编码,又叫做一位有效编码
有多少标签,就转化为多少行的单列矩阵,其本质就是将连续值转化为离散值。
这样可以直接直接将输出值直接输出,得到一个唯一值。
就像一个筛子,只留一个最大值,其他全部筛掉。
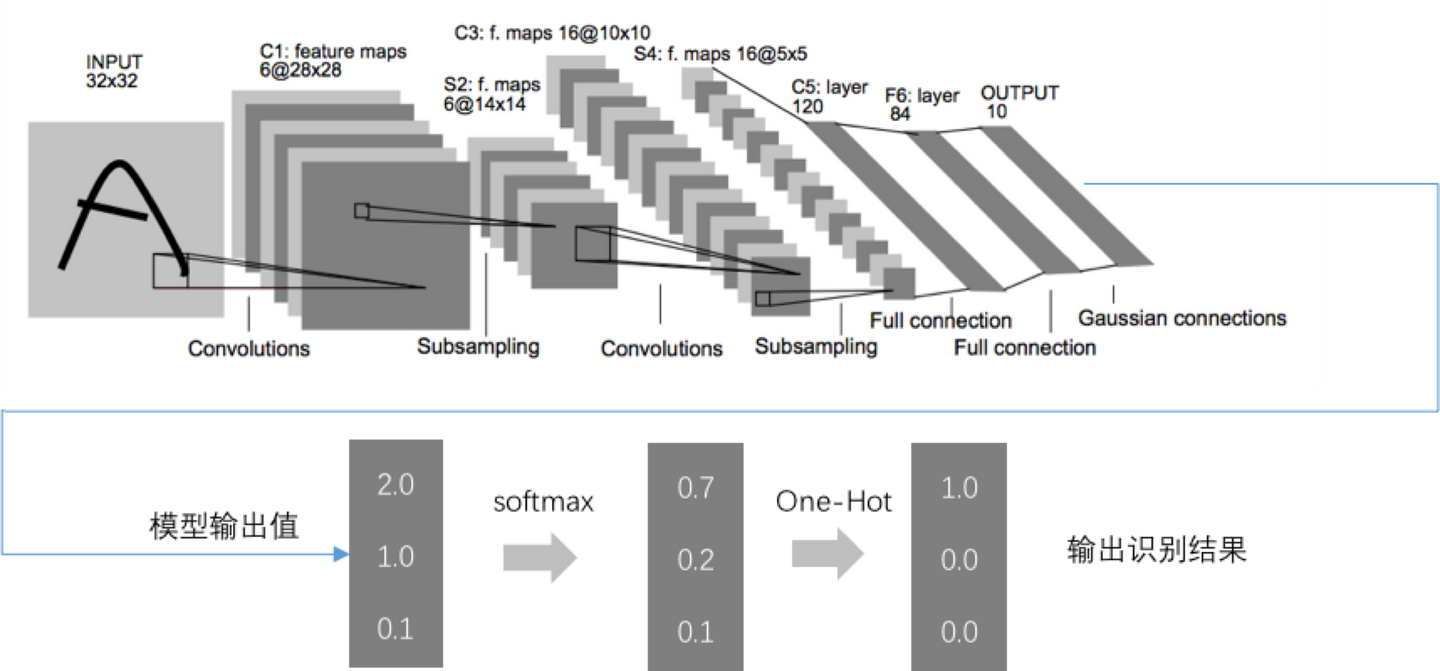
我们以LeNet为例串起来看(见下图),输出值经过全连接层,转化为10个标签值,然后经过softmax和one-hot
encoding,最终转化为唯一的识别标签值,就是我们想要的结果。
客观评价——交叉验证
讲完输出控制,我们再讲一下评价方法。
我们有一些数据,希望利用现有的数据去训练模型,同时利用这些数据去评价这个模型的好坏,也就是我们需要知道,这个模型的准确率是50%,还是90%,还是99%?
具体怎么去做呢?
最先想到的是,用全部的数据去训练,然后评价的时候,从中抽取一定数量的样本去做验证。这不是很简单嘛?
但是,这样不行。
想像一下,在高考考场上,你打开试卷,看了一眼之后高兴坏了。因为你发现这些试题你之前做练习的时候都做过。
其实是一个道理。如果拿训练过的数据去做验证,那得到的误差率会比实际的误差率要低得多,也就失去了意义。
那怎么办呢?我们需要把训练数据和最终评价的数据(也就是验证数据)要分开。这样才能保证你验证的时候看的是全新的数据,才能保证得到的结果是客观可靠地结果。所以我们会得到两个误差率,一个是训练集的误差率,一个是验证集的误差率,记住这两个误差率,后面会用到。
拿到数据的第一步,先把所有的数据随机分成两部分:训练集和验证集。一般而言,训练集占总数据的80%左右,验证集占20%左右。

训练的时候,随机从训练集中抽取一个批量的数据,去训练,也就是一次正向传播和一次反向传播。
这一轮做完之后,从验证集里随机抽取一定数量来评价下其误差率。
每做一轮学习,一次正向传播一次反向传播,就随机从验证集里抽取一定数量数据来评价其模型的准确率,一轮之后我们获得训练误差率和验证误差率。
接下来就是重点了,就是模型训练。
模型训练
实际训练模型的时候,我们会碰到两大终极难题,一个是欠拟合,一个是过拟合。
所谓欠拟合,就是训练误差率和验证误差率都很高。
所谓过拟合,就是训练集的误差率很低,但是验证集的误差率很高。
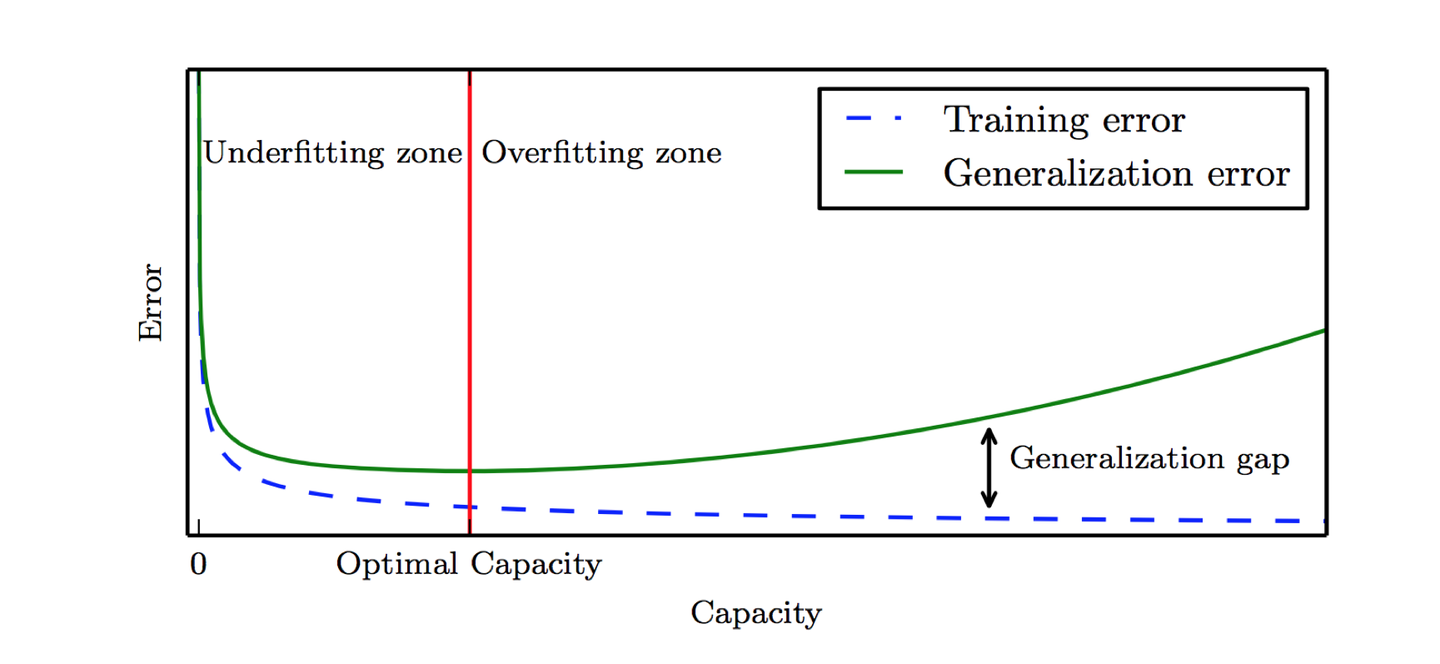
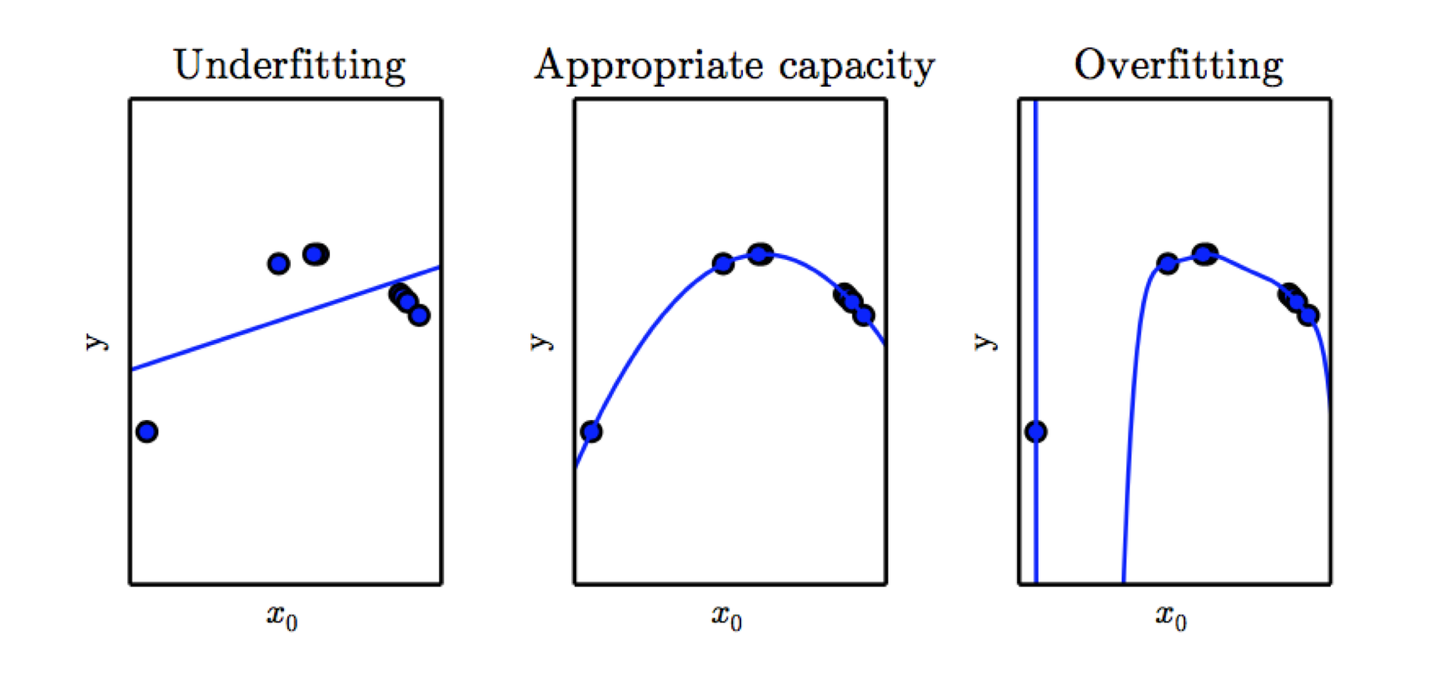
欠拟合和过拟合其实跟模型的复杂程度有很大的关系。
比如这张图里面,本来是抛物线的数据,如果用线性模型去拟合的话,效果很很差。如果用9次方模型去拟合的话,虽然训练集表现非常好,但是测试新数据的时候,你会发现表现很差。
欠拟合的原因其实比较简单,就是模型的深度不够,只需要把模型变得复杂一些就能解决。
过拟合的原因就比较多了,一般来说,简单粗暴的增加训练集的数量就能解决这个问题,但是有时候受限于客观条件,我们没有那么多数据。这时候我们就需要调整一些参数来解决过拟合的问题了。
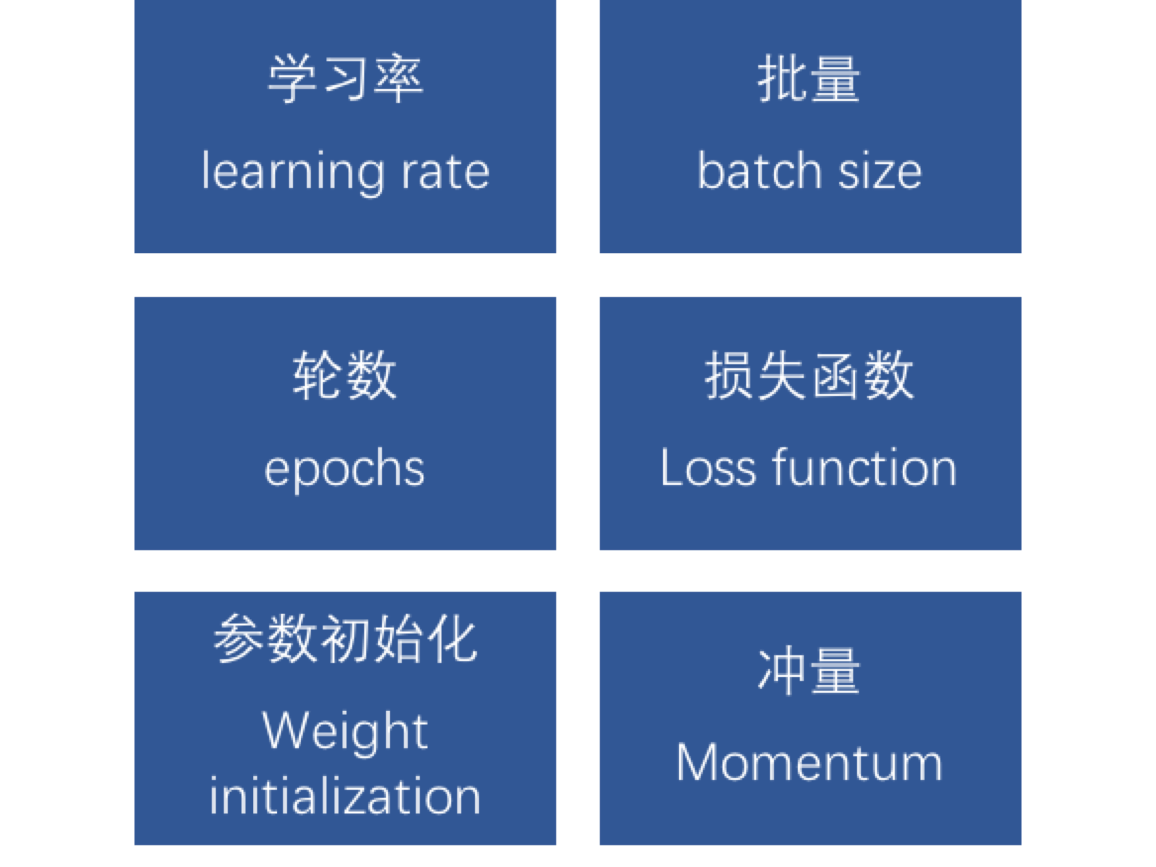
模型中能调整的参数叫做超参数。
调整这些参数,有时候有道理,有时候又没有道理,更多的是靠的一种感觉。有人说,调整超参数与其说是个科学,其实更像是一项艺术。
常见的调整的超参数有以下几种,下面我们逐项介绍一下。
学习率
上面提到的随机梯度下降中,我们会在梯度的前面加一个系数,我们管它叫做学习率,这个参数直接影响了我们误差下降的快慢。
当我们遇到问题的时候,先尝试调整下学习率,说不定就能解决问题。
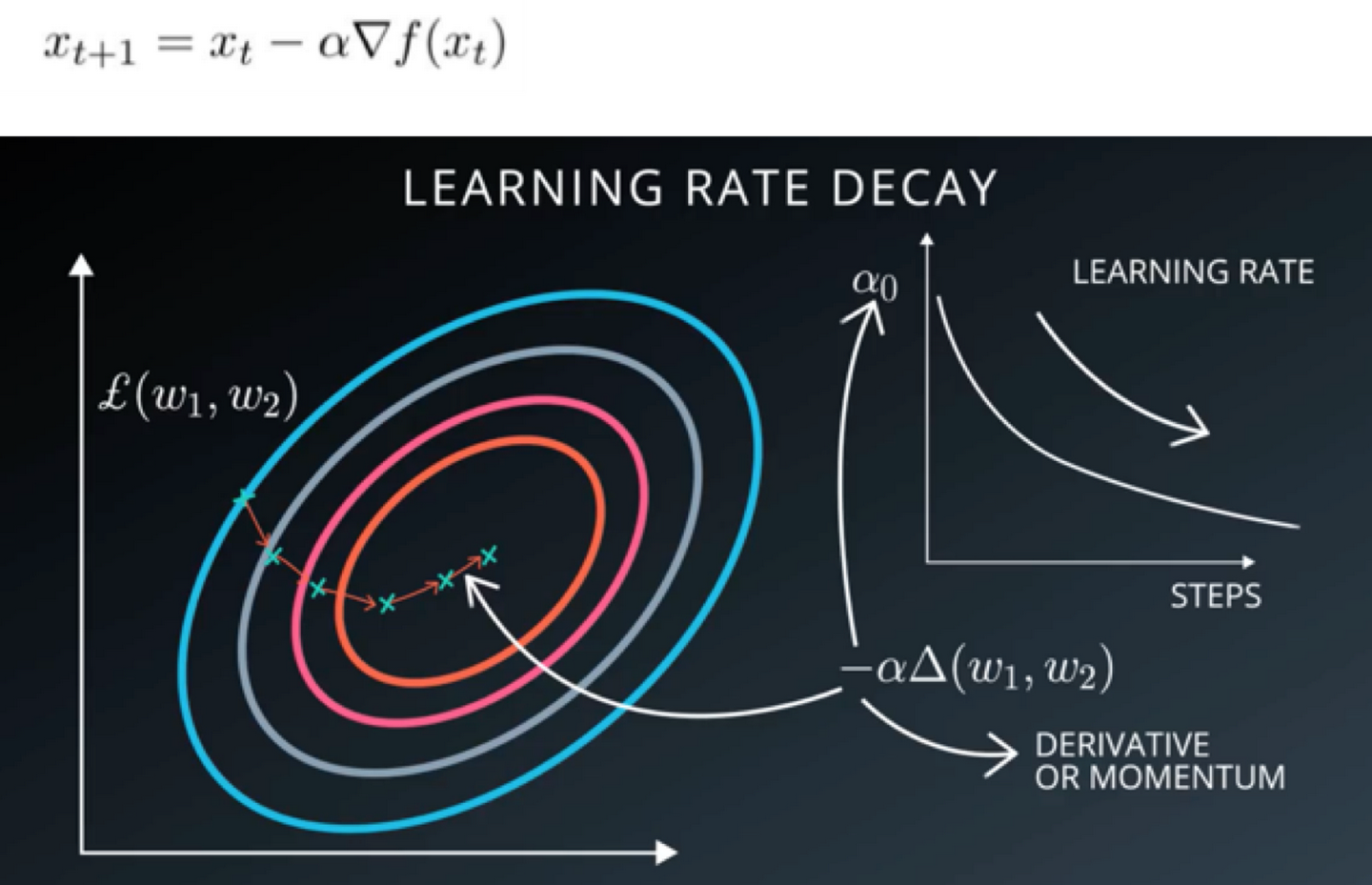
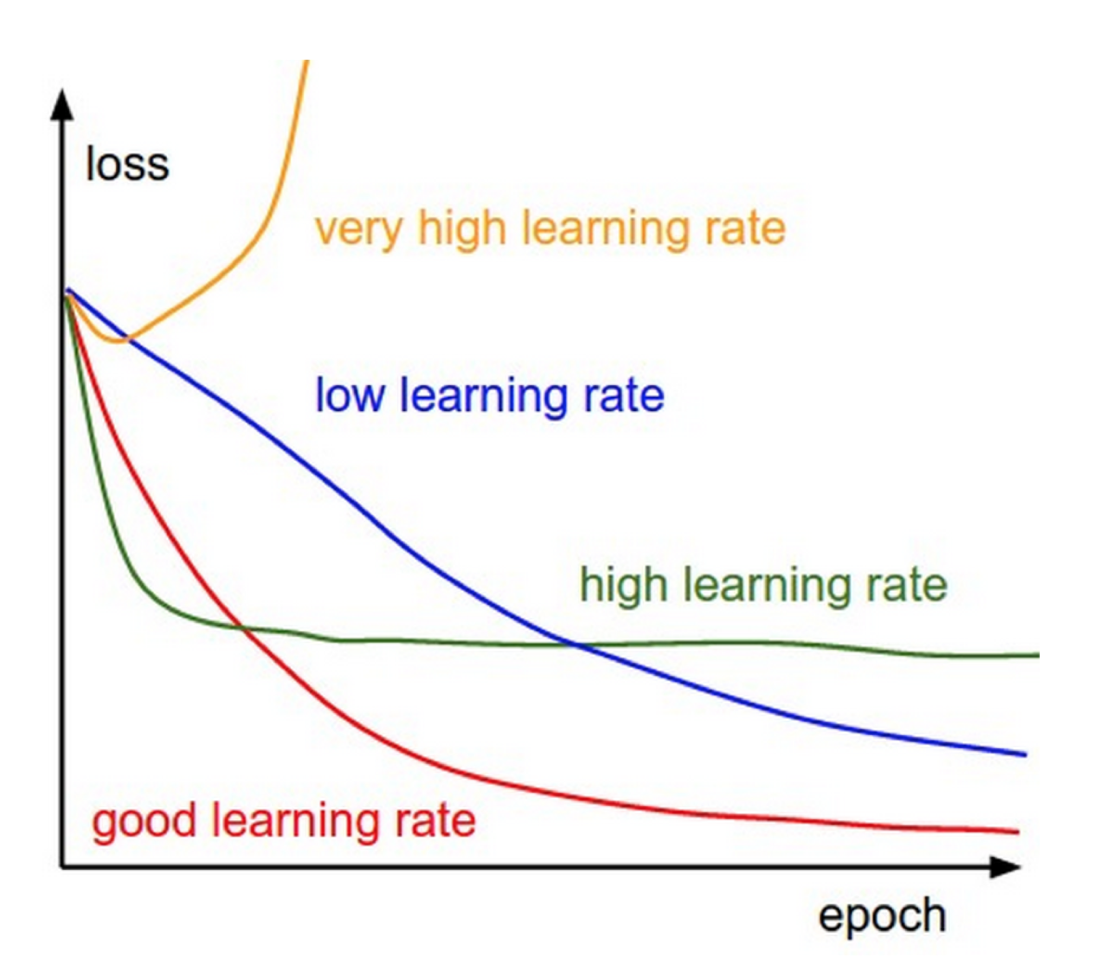
选择一个合适的学习率可能是困难的。学习率太小会导致收敛的速度很慢,学习率太大会妨碍收敛,导致损失函数在最小值附近波动甚至偏离最小值。下面这张图比较好的说明了学习率高低对模型误差下降的影响。
冲量Momentum
冲量的概念其实就是在梯度下降的时候,把上次的梯度乘以一个系数pho,加上本次计算的梯度,然后乘以学习率,作为本次下降用的梯度。pho一般选取0.9或者0.99。其本质就是加上了之前梯度下降的惯性在里面,所以叫做冲量。
有时候会采用冲量(momentum)能够有效的提高训练速度,并且也能够更好的消除SGD的噪音(相当于加了平均值),但是有个问题,就是容易冲过头了,不过总体来说,表现还是很不错的,一般用的也比较多。

下面这两张图也能看出来,SGD+冲量能够有效的加快优化速度,还能够避免随机的噪音。

轮数epochs
前面提到,一次正向传播,一次反向传播就是一轮,也就是一个epoch。
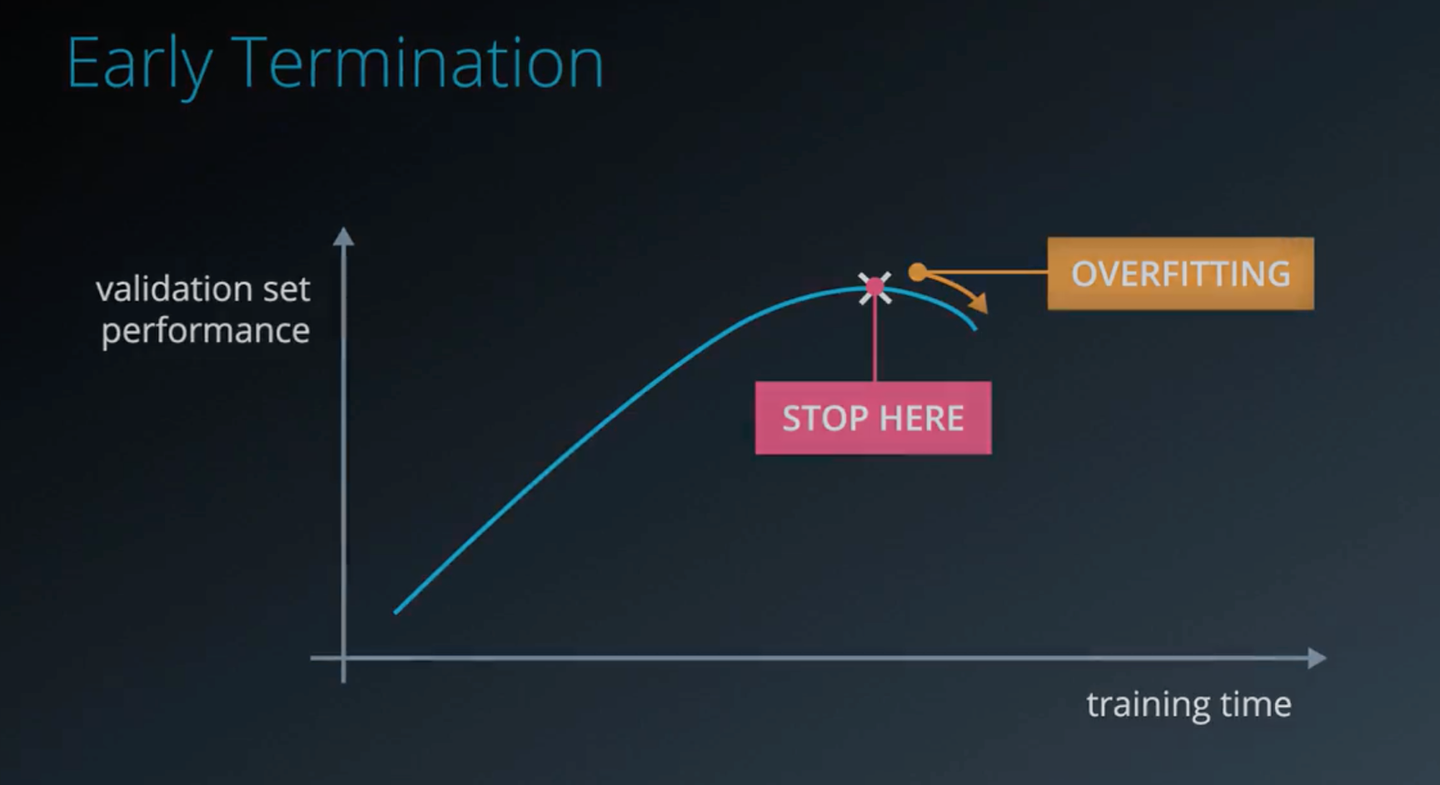
一般来说,轮数越多,其误差会越好,但是当学习的越多的时候,他会把一些不太关键的特征作为一些重要的判别标准,从而出现了过拟合。如果发现这种情况(下图),我们需要尽早停止学习。
参数初始化(weights initialization)
对于模型的所有参数,我们均随机进行初始化,但是初始化的时候我们一般会让其均值为0,公差为sigma,sigma一般选择比较大,这样其分散效果比较好,训练效果也比较好。

但是有时候仅仅调整超参数并不能解决过拟合的问题,这时候我们需要在模型上做一些文章,在模型上做一些处理,来避免过拟合。
Dropout
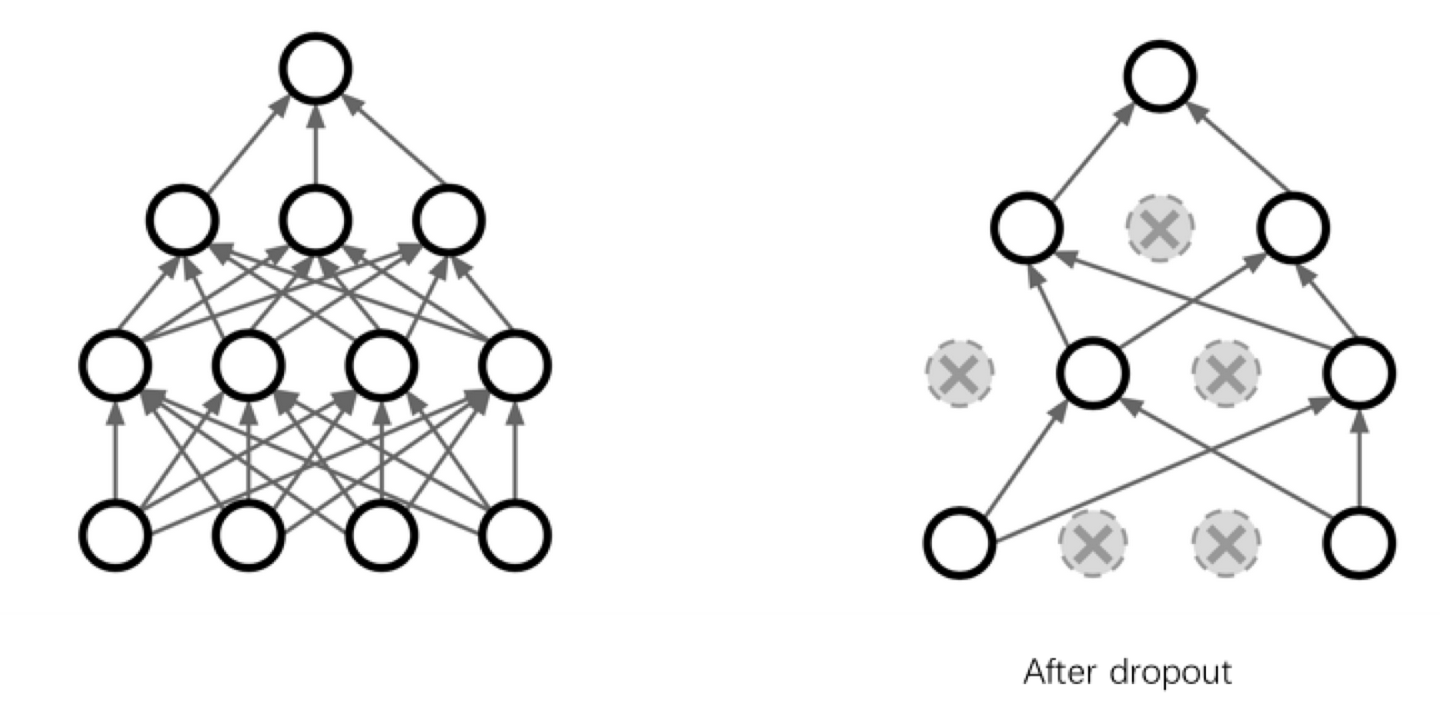
最常见的方法就是dropout.
drop的逻辑非常简单粗暴,就是在dropout过程中,有一半的参数不参与运算。
比如说公司里,每天随机有一般人不来上班,为了正常运转,每个岗位都需要有好几个人来备份,这样公司就不会过于依赖某一个人,其实是一个道理。
dropout的本质是冗余。为了避免过拟合,我们需要额外增加很多冗余,使得其输出结果不依赖于某一个或几个特征。
Pooling池化
除此之外,池化也是比较常用到的。
Pooling主要的作用为降维,降维的同时能够保留主要特征,能够防止过拟合。
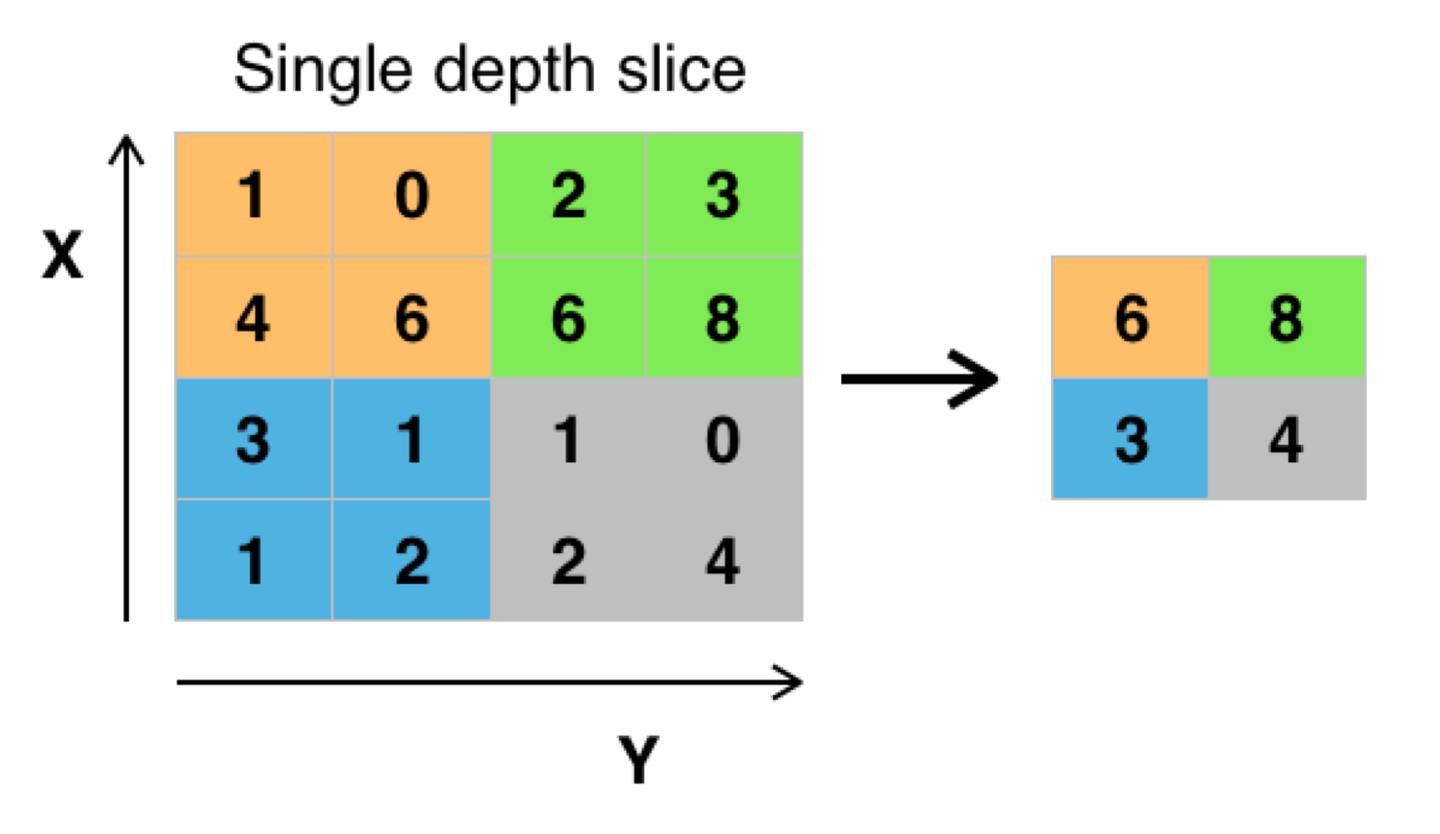
Pooling主要有两种:一种是最大化Pooling,还有一中是平均池化。
最大池化就是把区域的最大值传递到下一层(见下图),平均池化就是把区域内的平均值传递到下一层。
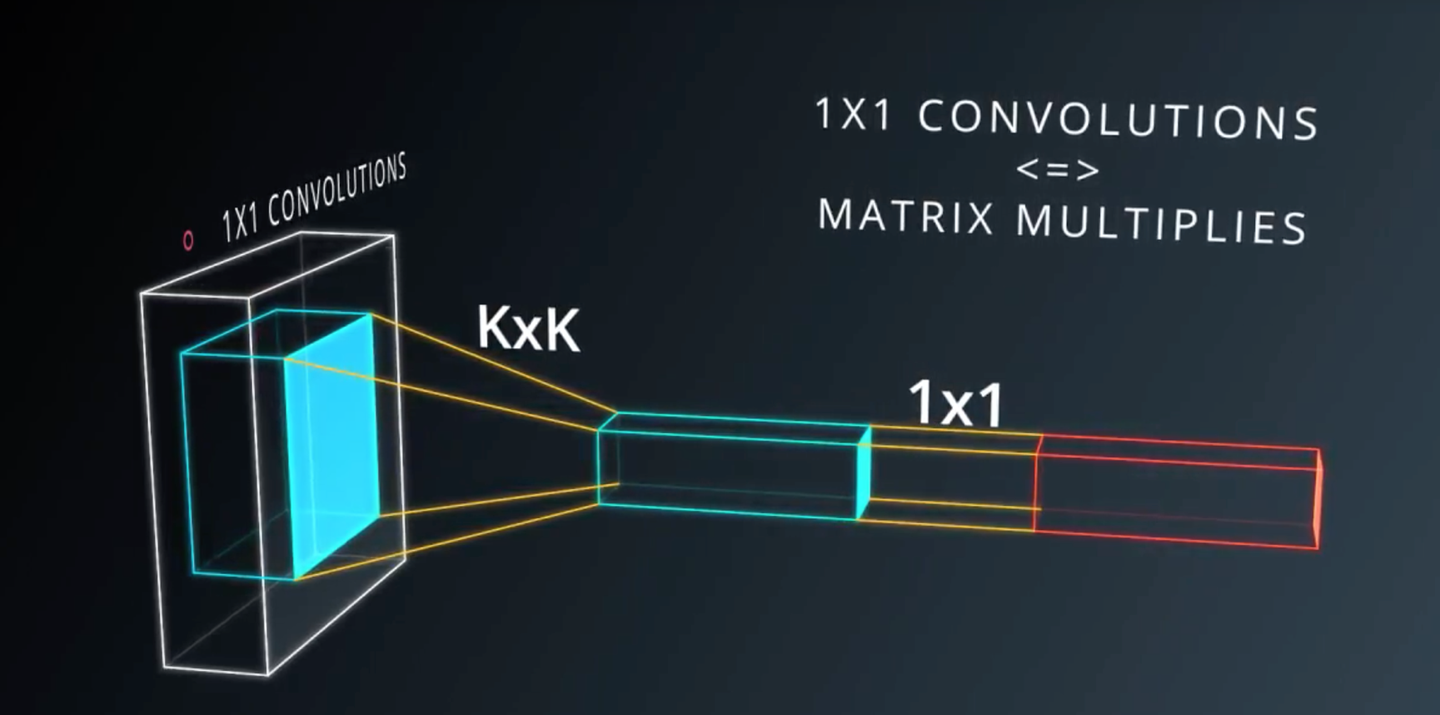
一般在Pooling之后会加上一个1x1的卷积层,这样能够以非常低的成本(运算量),带来更多的参数,
更深的深度,而且验证下来效果也非常好。
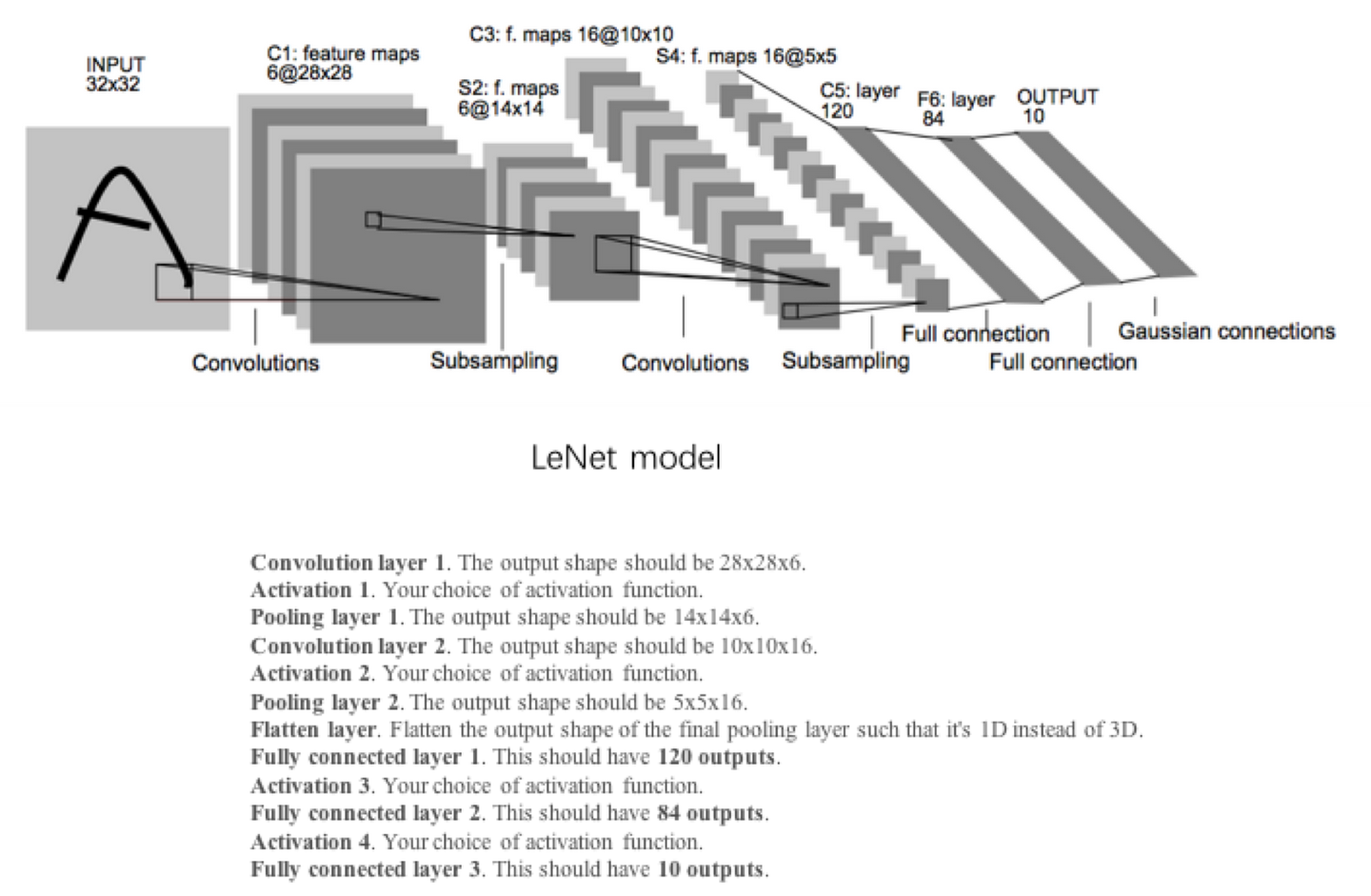
接下来我们可以分析下Lenet的数据,看的出来是卷积—>池化—>卷积—>池化—>平化(Flatten,将深度转化为维度)—>全连接—>全连接—>全连接。
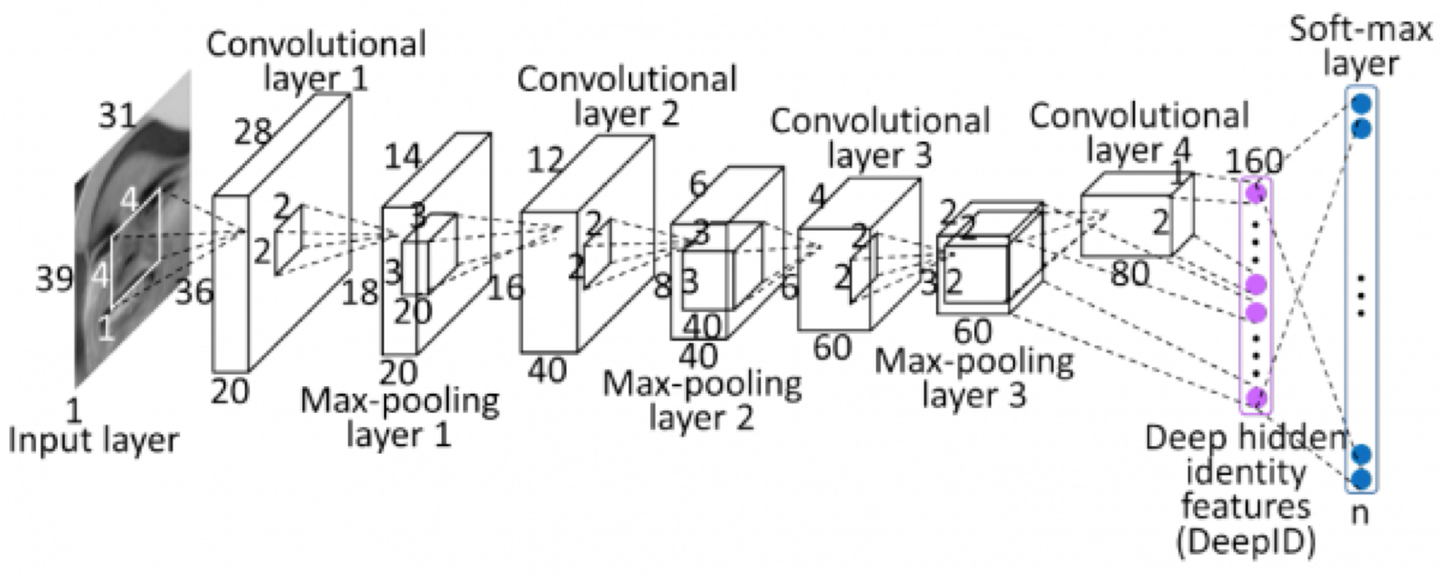
下面这个模型也比较简单,经过多层卷积、池化之后,平化,然后经过softmax转化。
截止到目前,我们又了解了训练模型所需要的技巧,如获取数据、预处理数据、模型搭建和模型调试,重点了解了如何防止过拟合。
恭喜你,现在你已经完全了解了深度学习的全部思想,成功晋级成深度学习高手了~
接下来我们看下深度学习的发展趋势。
深度学习发展趋势
目前深度学习在图像识别领域取得了很多突破,比如可以对一张图片多次筛选获取多个类别,并标注在图片上。

还可以进行图像分割。
在做图像分割标注的时候,难度很大,需要把每个类别的范围用像素级的精度画出来。这对标注者的素质要求很高。

还可以根据图像识别的结果直接生成语句。
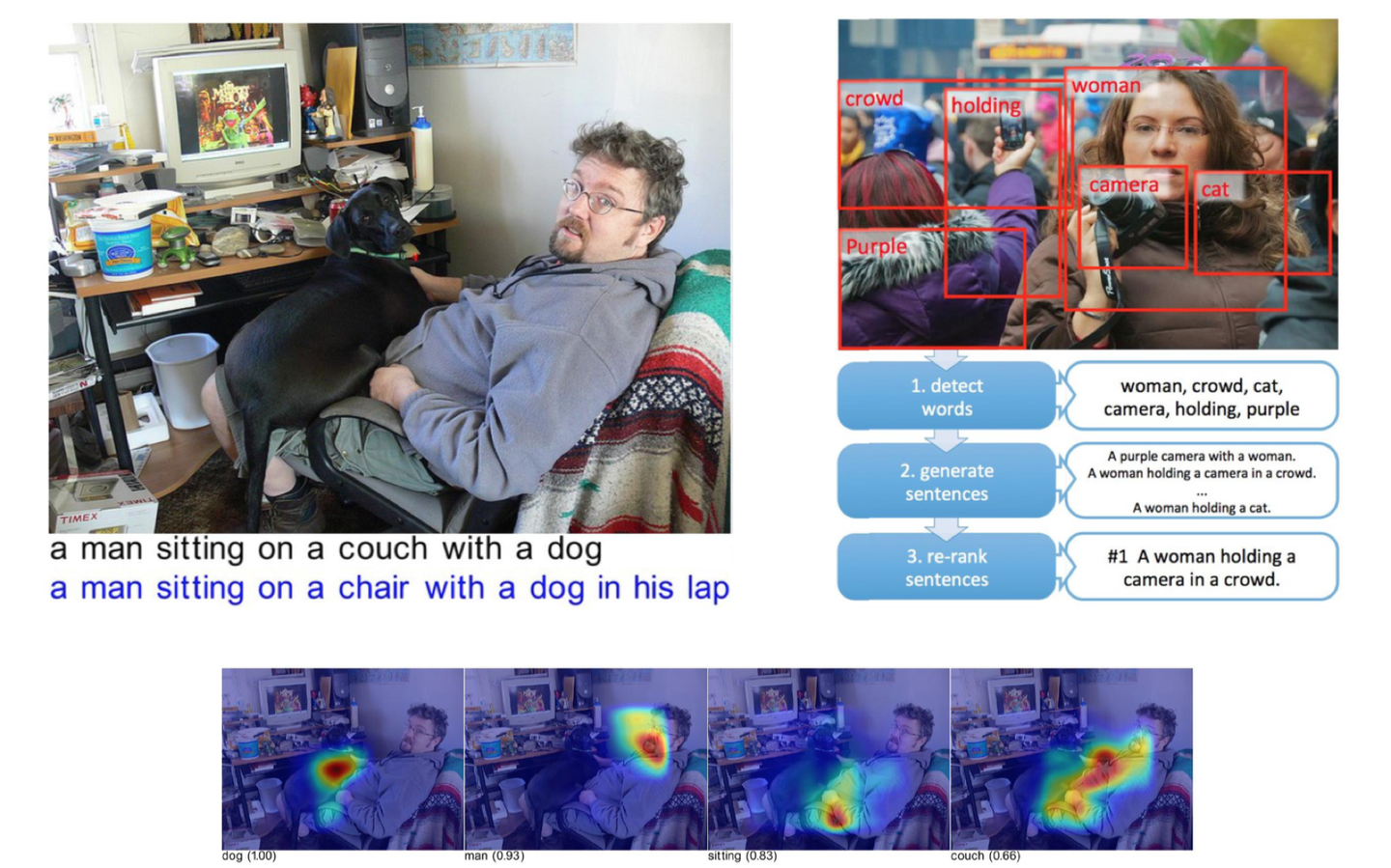
Google翻译可以直接将图片上的字母翻译过来,显示在图片上,很厉害。

最近媒体上很多新闻,说人工智能可以作诗,写文章,画画等等,这也都是比较简单的。

但是当前图像识别领域还存在一些问题,最大的就是其抗干扰能力比较差。
下图中左侧的图片为原始图片,模型可以轻易识别,但是人工加上一些干扰之后,对于肉眼识别不会造成干扰,但是会引起模型的严重误判。

这种情况可能会在某些很重要的商业应用中带来一些风险,比如在自动驾驶的物体识别时,如果有人故意对摄像头造成干扰,就会引起误判,从而可能会引起严重后果。
深度学习在自动驾驶领域有比较多的应用,下面是我做自动驾驶项目中的视频。
车辆识别:
行为克隆:
下图为加特纳技术曲线,就是根据技术发展周期理论来分析新技术的发展周期曲线(从1995年开始每年均有报告),以便帮助人们判断某种新技术是否采用。其把技术成熟经过5个阶段:1是萌芽期,人们对新技术产品和概念开始感知,并且表现出兴趣;2是过热期,人们一拥而上,纷纷采用这种新技术,讨论这种新技术;3是低谷期,又称幻想破灭期。过度的预期,严峻的现实,往往会把人们心理的一把火浇灭;4是复苏期,又称恢复期。人们开始反思问题,并从实际出发考虑技术的价值。相比之前冷静不少;5是成熟期,又称高原期。该技术已经成为一种平常。
当前机器学习和自动驾驶就处在过热期。
说到底,人工智能其实就是一种工具而已,只不过这项工具能做的事情多了一些而已。
未来人工智能会融入到生活中的方方面面,我们不可能阻挡这种趋势,所以我们唯一能做的,就是好好利用好这个工具,让未来的工作和生活更加方便一些。
送大家一句话:

关于人工智能威胁论
当前有些媒体在肆意宣扬人工智能威胁论,这其实是毫无道理的。
当人类对自己不了解的事物会本能的产生恐惧,越是不了解,越是会产生恐惧。
大家今天看下来,是不是也觉得人工智能也没啥。
其实就是因为了解了,所以才不会恐惧。我们只有了解他,才能更好的利用好它。
当前有部分无良媒体以及所谓的专家,在传播人工智能威胁论。
其实所谓的专家根本就不是这个领域的专家,如果他不是这个领域的专家,那他对这个话题其实就没有话语权,他说话的分量就跟一个普通人说的没什么区别。
流传比较广的,比如说某个坐在轮椅上的英国物理学家,对,没错,我说的就是霍金。
还有某国际著名新能源汽车公司的CEO,对,我说的就是Elon Musk。
他们对人工智能其实也完全是一知半解。
相信大家今天看完这篇文章之后,对人工智能的理解就可以秒杀他们了。
最近看到吴军的一句话,来解释人工智能威胁论,觉得非常恰当。
1 | 说一下人工智能的边界: |
最后分享一下学习资料:
- Stanford CS231n课程:http://cs231n.stanford.edu/
- MIT自动驾驶课程:https://selfdrivingcars.mit.edu/
- Deep Learning书籍: http://deeplearningbook.org
- Foundational papers: http://deeplearning.net/reading-list
- 快速上手 http://www.fast.ai/
- 图解机器学习 http://www.r2d3.us/visual-intro-to-machine-learning-part-1/
最后的最后,附上一个段子图,下排中间一脸虎视眈眈、苦大仇深、表情凝重的哥们,就是我们念叨的机器学习大神——Yann LeCun,目前是Facebook AI试验室的负责人。

最后,大家都看到这里了,请求大家关注下我的专栏和公众号“业界良新”不过分吧~
谢谢大家阅读。
计算机考虑院校
Carnegie Mellon University(CS专业排名第1名)
CMU拥有全世界最大的计算机学院,按研究方向分为很多系。申请者需具备较强的数学、编程和逻辑推理能力。
如果特别想去这所学校,建议同时申请MISM Program或者MS in INI Program,他们不在计算机学院,难度相对小一些。
Columbia University(CS专业排名第15名)
哥伦比亚大学的计算机系,设置在工程与应用科学学院(School of Engineering and Applied Sciences,即SEAS),分为MS in Computer Science(MS CS),MS in Computer Engineering (MS CE)两个项目。
如果你的三围在3.6+/4.0、105+和325+,也有较强的研究背景,你可尝试申请MS CS,如果相对弱一点,可以考虑申请MS CE。
University of Pennsylvania(CS专业排名第19名)
宾大的计算机系叫做Computer and Information Science(CIS),提供的以下硕士项目: MSE in Computer and Information Science,MSE in Computer Graphics and Game Technology,MSE in Robotics 和Master of Computer and Information Technology。宾大计算机科学在其工学院内一枝独秀,竞争非常激烈。
需要注意的是宾大的申请有两轮,第一轮截止日期是当年的11月15日,第二轮截止日期是次年的3月15日,两轮申请的难度都很大。其中MCIT接受各种转专业申请。
Northwestern University(CS专业排名第34名)
西北大学的计算机专业,设置在Electrical Engineering and Computer Science系,这个系开设了三个专业,即EE, CE和CS,其中CS的申请难度最大。
如果你很想去西北大学,建议可以先申请EE或CE,然后再去转专业到CS,转专业相对来说还是比较容易的。西北大学建议尽早申请,也可尝试直接申请博士,审核时会同时考虑硕士录取可能性。
University of California- Los Angeles(CS专业排名第13名)
洛杉矶的计算机系,有两种硕士学位:论文型和综合性考试型。
学校对三围有明确的要求,TOEFL总分87+(写作25+,口语24+),录取学生的平均GPA平均GPA:3.67/4.00,GRE单项平均分:V: 157 (74%); Q: 167 (95%);AW: 3.7 (41%)。
另外,申请人还需要很强的计算机专业知识和研究背景
9. New York University(CS专业排名第30名)
纽约大学的研究生院,开设了计算机专业,其硕士项目有:MSCS 和 Masters in Information Systems ,大学地理位置比较好,申请人不少。另外,新加入的工学院的计算机项目比较好申请。
Washington University IN St. Louis(CS专业排名第40名)
华大的计算机专业设置在Computer Science &Engineering系,这个系提供三种硕士项目,即MS CS, MS CE和MEng CSE,其中CS的申请难度最大。
如果你非常想去这个学校,建议你可以先申请CE,然后去那边多选修一些CS的课程,若表现优异的话,就有机会转到CS,或者你可以选择申请MEng项目。对于本科专业是物联网等非正统CS的学生,还可以选择申请Master of Science in Information Systems (MSIS)项目,申请难度会相对小一些。这个项目需要面试,但是比较容易,网上有很多相关的面经。
University of Southern California(CS专业排名第20名)
南加州大学计算机专业,有广泛的硕士项目:MS CS;和具体的分支项目:Computer Security, Game Development, Computer Networks, Software Engineering,High Performance Computing and Simulation, Intelligent Robotics, Multimedia andCreative Technologies, Data Science.。你可以根据自己的研究背景或者喜好来选择。南加大还有专门接受转专业申请的项目,MS CS (Scientist and Engineer),优秀学生很容易申请到。
美国绝大部分学校都开设了计算机科学专业,此专业基本开设在工学院下。
总的来说,计算机专业前20名的学校可分成三类:
A.4个最为优秀的CS Program:Stanford,MIT,U.C.Berkeley,CMU.
B.6个其他前10名的:UIUC,Cornell,U.Washington,Princeton,U.Wisconsin- Madison和 U.Texas-Austin.
C.其他非常非常优秀的CS:CalTech,U.Maryland-College Park,UCLA,U.Michigan, GIT,Brown,Harvard,Yale,Purdue和 Rice.
gre1
\1. It is a paradox of the Victorians that they were both _____ and, through their empire, cosmopolitan.
A. capricious
B. insular
C. mercenary D. idealistic
E. intransigent
\2. My grandma has a strong belief in all things _____: she insists, for example, that the house in which she lived as a child was haunted.
A. clamorous
B. invidious
C. numinous D. empirical E. sonorous
\3. The (i)_ of molecular oxygen on Earth-sized planets around other stars in the universe would not be (ii)_ sign of life: molecular oxygen can be a signature of photosynthesis (a biotic process) or merely of the rapid escape of water from the upper reaches of a planetary atmosphere (an abiotic process).
\4. Given the (i)_ the committees and the (ii)_ nature of its investigation, it would be unreasonable to gainsay the committee’s conclusions at first glance.
\5. The skin of the poison dart frog contains deadly poisons called batrachotoxins. But the (i)_ of the toxins has remained an enigma, as the frog does not (ii)_ them. Now an analysis suggests that the melyrid beetle is the source. Collected beetle specimens all contained batrachotoxins, suggesting that these beetles are (iii)_____ by the frogs.
| A. dearth | D. a controversial |
|---|---|
| B. presumption | E. an unambiguous |
| C. detection | F. a possible |
| A. sterling reputation of | D. superficial |
|---|---|
| B. lack of finding of | E. spontaneous |
| C. ad hoc existence of | F. exhaustive |
| A. effect | D. pressure | G. eaten |
|---|---|---|
| B. origin | E. produce | H. neutralized |
| C. purpose | F. suffer from | I. poisoned |
微信公众号:张巍⽼老老师GRE 第 8 ⻚页
真经GRE GRE填空机经1250题 难度分级版
\6. Now that photographic prints have become a popular field for collecting, auctions are becoming more (i). It is not just the entry of new collectors into the field that is causing this intensification. Established collectors’ interests are also becoming more (ii). Those who once concentrated on the work of either the nineteenth-century pioneers or the twentieth-century modernists are now keen to have (iii)_____ collections.
\7. The beauty of the scientific approach is that even when individual researchers do _____ bias or partiality, others can correct them using a framework of evidence on which everyone broadly agrees.
A. overreact to
B. deviate from C. succumb to D. recoil from E. yield to
F. shrink from
\8. The reconstruct known work is beautiful and also probably _____: it is the only Hebrew verse written by a woman.
A. singular
B. unique
C. archaic
D. counterfeit E. valuable
F. fake
\9. In a book that inclines to _____, an epilogue arguing that ballet is dead arrives simply as one more overstatement.
A. pessimism
B. misinterpretation
C. imprecision D. vagueness E. exaggeration F. hyperbole
\10. The political upheaval caught most people by surprise: despite the _____ warnings of some commentators, it had never seemed that imminent.
A. stern
B. prescient
C. prophetic D. indifferent E. repeated F. apathetic
| A. competitive | D. fickle | G. comprehensive |
|---|---|---|
| B. tedious | E. wide-ranging | H. legitimate |
| C. exclusive | F. antiquarian | I. impressive |
微信公众号:张巍⽼老老师GRE
第 9 ⻚页
真经GRE GRE填空机经1250题 难度分级版 section 2 easy
\1. Among the Meakambut people of Papua New Guinea, legends are associated with specific caves in the Sepik region, and these legends are _____: only the cave owner can share its secrets.
A. impenetrable
B. immutable
C. proprietary
D. didactic
E. self-perpetuating
\2. We often regard natural phenomena like rainfall as mysterious and unpredictable; although for short time spans and particular places they appear so, in fact on a truly global scale, nature has been a model of _____.
A. reliability
B. diversity
C. complexity D. plasticity
E. discontinuity
\3. The economic recovery was somewhat lopsided: (i)_ in some of the industrial economies while (ii)_ in others of them.
\4. Although trains may use energy more (i)_ than do automobiles, the latter move only when they contain at least one occupant, whereas railway carriages spend a considerable amount of time running up and down the tracks (ii)_, or nearly so.
\5. Most capuchin monkey conflict involves such a (i)_ repertoire of gestural and vocal signals that it is difficult for researchers to tease apart the meanings of the individual signals. This (ii)_ is (iii)_____ by the fact that many signals seem to shift in meaning according to the context in which they are produced and the developmental stage of the individuals producing them.
| A. unexpected | D. robust |
|---|---|
| B. feeble | E. turbulent |
| C. swift | F. predictable |
| A. lavishly | D. vacant |
|---|---|
| B. efficiently | E. unimpeded |
| C. routinely | F. overlooked |
| A. precise | D. problem | G. augmented |
|---|---|---|
| B. rich | E. opportunity | H. ameliorated |
| C. straightforward | F. oversight | I. anticipated |
微信公众号:张巍⽼老老师GRE 第 10 ⻚页
真经GRE GRE填空机经1250题 难度分级版
\6. Within the culture as a whole, the natural sciences have been so successful that the word “scientific” is often used in (i)_ manner: it is often assumed that to call something “scientific” is to imply that its reliability has been (ii)_ by methods whose results cannot reasonably be (iii)_____.
\7. Members of the union’s negotiating team insisted on several changes to the company’s proposal before they would support it, making it clear that they would _____ no compromise.
A. disclose
B. reject
C. brook
D. tolerate E. repudiate F. weigh
\8. Wilson is wont to emphasize the _____ of ants: how ants with full stomachs will regurgitate liquid food for those without, or how the old will fight so the young can survive.
A. beneficence
B. altruism
C. unpredictability D. intelligence
E. fecundity
F. fertility
\9. During the Renaissance, the use of optical lenses, which were capable of projecting images onto blank canvases, greatly aided artists by allowing them to accurately observe and depict the external world; in other words, these lenses were instrumental in conveying _____.
A. idealism
B. optimism
C. ambition
D. realism
E. sanguinity
F. verisimilitude
\10. The professor’s habitual air of _____ was misleading front, concealing amazing reserves of patience and a deep commitment to his students’ learning.
A. cordiality
B. irascibility
C. disorganization D. conviviality
E. diffidence
F. exasperation
申请学校
作者:AdmitWrite硕士留学
链接:https://www.zhihu.com/question/64316943/answer/1214032948
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
个人背景及申请结果
本科专业:物联网工程 GPA:84(WES 3.46) 22/120 TOEFL:106(S22) GRE:153+168+3.5 科研经历/paper:学院里一段比较水的科研和一段web开发,无paper 竞赛:美赛H,大创国家级
申请结果(括号内为提交申请的日期和收到结果的日期)
AD
CMU,MITS(1.13/4.17);CMU,eBiz(12.12/1.27);UChicago,CS(12.5/1.28);Duke,ECE(1.21/3.11);NYU-Tandon,CS(1.17/3.24)(奖学金4000刀);Brandies,CS(1.15/4.19)(奖学金10000刀)
Rej
UPenn,CIS(11.14/12.16);Columbia,CS(1.2/3.7);Dartmouth,CS(12.14/2.28);CMU,MISM-21(1.9,3.31);UCSD,CS(12.9/3.7);JHU,CS(1.15/4.16)
Pending
USC,CS-general(12.5);CMU-SV,SE(12.14);Cornell,CS-Meng(1.6);UMich,MSI(1.13);NWU,CS(1.16)最后Pending的结果是USC的CS general变成了春季的AD,其他全是Rej。
作者:纽约大叔
链接:https://zhuanlan.zhihu.com/p/137654432
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一、专为非计算机背景学生设置的项目
1.芝加哥大学
芝加哥大学计算机系专门设置了一个针对转专业学生的项目:MS in Computer Science program。与其他普通的MSCS不同,该项目主要多了两门课程:Concepts of Programming和Math for Computer Science: Discrete Math。
● 适合对象:无任何编程或计算机背景的申请人
● 前置课程:编程基础、集散数学等
● 学制:9门课程学位:2个月前置课程+9个月正式课程;12门课程学位:2个月前置课程+15个月正式课程(含夏季实习)
院校背景:芝加哥大学的计算机系是美国最强的计算机系之一,最大特点就是注重计算机与商业需要的结合,并运用到商业和市场应用及各种决策分析中。
2.宾夕法尼亚大学
宾夕法尼亚大学的Master of Computer and Information Technology program(MCIT)项目是专门为非计算机背景的学生设置的。该项目主要有5门必修课:计算机科学数学基础、计算机系统概述、数据结构和软件设计、软件发展概述以及计算机系统编程和算法等。
该项目历届录取学生的背景很多样化,包括法律、数学、文学、历史、化学、医学等。
● 适合对象:无任何编程或计算机背景的申请人
● 前置课程:6门前置课程
● 学制:一年半到两年
院校背景:除MCIT项目外,同系还开设有CIS,CGGT,EMBS,Robotics等硕士项目。CS专业的学生很多会选择申请CIS项目,对图像感兴趣的学生会考虑CGGT,对嵌入式系统感兴趣的学生会考虑EMBS,对机器人感兴趣的学生会考虑Robotics项目。
另外,宾大的MCIT项目在为数不多的转专业项目中,算是难度最高的一个项目了。海本学生,至少3.7以上的GPA,GRE330以上,会有比较大的机会。
3.布兰迪斯大学
布兰迪斯大学的计算机科学硕士 MA in Computer Science for Non-majors 是针对非计算机专业背景人士开设。与普通的CS专业相比,该专业多了一个学期的课程,主要补的是计算机的基础课程。
● 适合对象:无任何编程或计算机背景的申请人
● 前置课程:4门本科计算机基础课程 COSI 11a, COSI 12b, COSI 21a, and COSI 29a
● 学制:2年,四个学期
院校背景:该项目不仅提供计算机基础相关的课程学习,也提供一些热门领域的课程,如大数据。选修课涵盖各个领域,学生可以根据自己的兴趣去选择。另外,项目提供较为丰富的资助机会,将有可能拿到奖学金。
4.南加利福尼亚大学
南加利福尼亚大学计算机方向针对转专业学生重点推荐的是计算机科学硕士—科工方向Master of Science in ComputerScience - Scientists and Engineers。科工方向是37个学分,比其他方向多了5个学分,也会有一些计算机科学基础和预备课程。
● 适合对象:适合计算机背景有限、拥有工程或理科专业背景的学生申请
● 学制:两年
院校背景:南加利福尼亚大学的计算机系Department of Computer Science方向非常齐全,共开设了8个硕士课程,每个program计划招生40人左右,人数庞大,因此申请难度要低于其他院校。
5.东北大学
美国东北大学计算机学院专门针对转专业学生设置的项目为Align MS in CS (For people new to CS)。
相比其他项目,本项目多了四门计算机的基础课程:计算机基础离散结构、计算机系统/算法和面向对象的语言。该项目在课程上完以后,学校还会推荐实习。目前和这个项目合作的公司主要有Amazon , Facebook,Google以及美国有名的差旅费管理服务商Concur,房产信息平台Zillow等。
● 适合对象:针对那些非CS专业但是想要找CS相关工作的学生
院校背景:近年来,由于地理位置、COOP政策、招生规模扩大等因素,东北大学的CS项目热度非常高。因此,该其项目的申请难度波动也非常大。按前几年的录取趋势来看,普通985学校3.5左右的GPA,GT中等偏上就有很大机会被录。
如果对美国CS专业申请有任何疑问,可以添加我的微信免费咨询,微信:bayergogo,还可以免费领取托福、雅思、GRE、GMAT等学习资料。
二、其他对转专业申CS较友好的项目
1.卡耐基梅隆大学
卡耐基梅隆大学拥有全美最大的计算机学院,其CS下的细分专业是十分全面。对于转专业申请,首先要提的就是设置在计算机学院下的Master of Science in InformationTechnology (MSIT) Programs in eBusiness Technology(EBIZ)项目。
● 课程设置方面,该项目十分重视动手能力,课程也完全由项目组成,包含16个Task和一个Practicum。因此在申请材料中一定要突出动手能力或是领导经验。
● 招生方面,该项目每年招生60人左右,会录取很多非CS、非技术出身的申请者。录取者构成基本1/3为CS专业,1/3为电子,化工工程类专业,剩下1/3则是商科/人文(金融,经济,会计等)专业。
● 申请方面,该项目比较看重雅思/托福成绩,对拥有理工科背景的申请者会适当放宽托福口语要求,而文商科类申请者托福或雅思成绩要求就比较高。
2.纽约大学
纽约大学分别在文理学院和工学院下设置了CS的master项目。尽管如此,两个学院的CS项目排名大大不同,分别为29和70。其中,工学院的CS提供preparatory bridge courses, 是专门针对CS背景较弱的学生设置的,所以转专业申请的话,可以申请工学院的CS,难度相比文理学院的CS要低。
学校分层
作者:申荣教育
链接:https://zhuanlan.zhihu.com/p/75261927
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
学校分档

1、哥伦比亚大学
哥大的 CS 系成立于 1979 年,研究的领域涵盖了 CS 领域的各个研究方向,包括计算生物学、计算机工程、算法和用户界面、安全与隐私、软件系统、计算机理论、视觉与机器人等等。共开设有 25 个研究小组和实验室。其中,实力较强的专业方向包括机器学习、安全与隐私、软件系统以及计算机理论。
申请特点
该校较为注重申请者的综合素质,需要申请者在硬件和软件方面有一定的积累。在硬件方面,GPA 85 分左右,TOEFL 100 分左右,GRE325 以上的条件拿到录取有较大的保障。
2、卡耐基梅隆大学
对于一般的美国院校来说,计算机科学只是设置为一个系,即Department of Computer Science,然而,CMU 对 CS 的建设非常有诚意,直接就开设成为了一个院——School of Computer Science。CMU 拥有数量庞大的教授队伍,多位曾获图灵奖,此华丽阵容,使得 CMU 当之无愧地成为 CS 专排第一的牛校。
基于CMU研究人员的庞大,本校涵盖了计算机科学的所有研究方向,不单细致地做每一个研究方向,并且将这些研究方向的应用也有较为深入的研究。
申请特点
硕士课程有较大的面试几率。曾经有申请软件工程和游戏设计的客户收到了 CMU 的面试电话。面试的内容都非常带有本所的特色,如软件研究所注重软件项目经历,需要客户口头描述下自己的项目经历。
从整体来看,CMU 比较看重研究背景。
3、纽约大学
研究内容包括算法与理论,密码学,计算生物学,计算机图形图像与用户界面,形式化方法,机器学习与知识呈现网络,科学计算等。CS 的特色在于与别系(尤其是数学系)合作非常紧密,CS 学生跨学科学习和合作的机会较多,如化学,物理,生物,神经科学等。
申请特点
NYU 开设了 MS 和 Ph.D 学位,对于 Master 的申请者,学校校求 T100,G 每部分在85%,或至少一部分达 92%;除此以外,还要求申请者掌握 C++,Java,汇编语言,操作系统等。
4、加利福尼亚大学洛杉矶分校
历史上 UCLA 的 CS 曾经一度辉煌,上到过第 6,由此可见UCLA 的强大程度。UCLA 辉煌的历史可能在于它对 Internet 的发展所作出的巨大贡献,它作为INTERNET 的先驱,地处阳光灿烂的南加州,应当成为 CS 学生的乐土。UCLA 的 CS 系很大,教授数量也很多。
申请特点
UCLA 的录取难度向来很高。外本和港本的学生在申请时会容易一些,而国内名校的学生在申请时会有一些优势。UCLA 除了看重硬件条件以外,也是非常看重申请者的研究背景。因此,如果只硬件好的学生在很多情况下也拿不到 UCLA 的录取。
5、伊利诺伊大学香槟分校
伊利诺伊大学香槟分校从美国国家科学基金获得研究经费量,年年在全美名列第一。计算机系和很多著名的公司保持着合作关系,例如拥有数百万美元的并行计算和云计算研究中心。
学生有很多实践机会,着重计算机和其他学科的交叉研究。本专业的学生在毕业以后可以继续攻读与计算机科学相关的更高层次的学位课程,也可以直接就业。
申请特点
计算机系写明了对于申请学生 GPA 的要求,并且告知历年录取的学生平均 GPA 为 3.7。由此说明学校对于学生的本科硬件条件有着比较严格的要求。
6、西北大学
西北大学计算机专业研究领域包括:Artificial intelligence, Human computer interaction.,Distributed interactive systems., Theoretical computer science, Programming languages, Computer graphics and human computer interfaces, Robotics, Parallel processing, Computer architecture,Large-scale systems.
申请特点
西北大学的 CS 专业近两年,也成为那些要去综合排名前 20 的申请者的一个不错的选择。从发放的录取结果看来,该校的 CS 专业并不算很难申,而且发的录取也相对多。同时也适合非 CS 专业的学生申请,以往就看到有一些 EE的学生拿到录取。

7、华盛顿大学圣路易斯分校
CS专业开设在工程与应用科学学院,总的来说工程学院确实不是WUSTI的一个强势学院,但是最近几年学校已经在大力发展。计算机科学与工程系共开设了3个研究生学位项目:计算机科学理学硕士,计算机工程理学硕士,计算机科学与工程硕士。
申请要求
GPA一般在3.3左右,GRE平均320,托福平均100分。
8、南加州大学
研究领域包括 1 Artificial Intelligence, Agents, Natural Language; 2 Databases and Information Management; 3 Graphics Games & Multimedia; 4 Parallel and Distributed Computations; 5 Robotics, Brain Theory, and Computational Neuroscience; 6 Software Systems and Engineering; 7 Systems, Distributed Systems, Communication Networks; 8 Theory and Computational Sciences 八大方向。每个大的方向下设很多实验室和研究中心,分别有不同的教授带领着。
申请特点
招生人数较为庞大,这也是相对而言在专业排名前 30 的学校中它的申请难度大大低于其他高校的原因。但是随着历年来很多学生扎堆申请 USC 的 CS 专业,学校对于申请者的要求也在提高。
9、加利福尼亚大学尔湾分校
UCI 的 CS 系设置于该校的信息与计算机科学学院下,是该院最大的系。
研究方面,该系涉及到了 CS 领域下在的 11 个研究方向,包括:算法与复杂性,人工智能与机器学习、生物医学信息学、计算机体系结构与嵌入式系统、计算机图形学与可视化计算、数据库与数据挖掘、网络与分布式系统、编程语言与编译、安全隐私与密码学、科学计算以及普适计算。
其中,网络与系统、人工智能和计算机安全这几个方面的研究实力最为突出。
申请特点
UCI 是 UC 系列的院校里录取中国学生较多的院校之一,CS 专业更是如此,总的申请难度并不是太高,不过,就会很注重硬件成绩,GPA 3.5 左右,GRE 321以上,TOEFL 100 分以上的申请者才有较大的录取可能性。
10、东北大学
东北大学的 CS 系成立于 1982 年,设置在计算机与信息科学学院下面,从事 4 大专业领域,包括健康信息学、信息安全、网络科学、软件可靠性的研究。
这 4 大专业领域又可以分为11 个研究组,包括:算法与理论、人工智能、形式化方法、人机交互、信息检索与数据挖掘、网络安全、编程语言、机器人技术、软件工程、社会网络以及系统等研究组。
申请特点
该校属于申请热门院校,被很多申请者拿到作为保底的选择。过去几年来看,它的录取标准是 GPA 3.0 以上,GRE 320分以上,TOEFL 90 分以上这样的水平,但东北的 CS 专业的申请难度已经逐年提高。

11、雪城大学
雪城大学的 CS 系与 EE 系合并在同一系下,这也是作为雪城的办学特色,因为学生可以跨学科学习。学校非常重视研究能力,学生在学习过程中也有机会参与到研究项目当中。
由于 EECS 合办的原因,该系的研究方向是有比较大的交叉性的,共有 11 个研究方向。其中属于 CS 领域的专业方向比较少包括:人工智能、网络安全,硬件设计和计算机体系结构。
申请特点
雪城的录取难度比第三档的其它学校要高一些,是介于第二档跟第三档间的。学校每年发放的录取非常多,门槛也较低。申请者的条件只要达到 GPA 80 分左右,GRE315以上,TOEFL 95分以上,拿到该校的录取就不难。
12、佛罗里达大学
CS设置在名为计算机信息科学与工程系下,此系同时归属两个大院,college of engineering 和college of liberal arts and science。该 department 的研究领域有:计算机图形模拟与艺术,计算机系统,数据库与信息系统,高能计算/应用算法,智能系统与计算机视觉。
申请特点
一般 GPA83 以上,GRE320 以上,TOEFL90 以上都有较大可能获得录取,并且此校有一个发AA 奖的传统,即无论硕士博士,条件相对较好的申请者都能拿到一半的学费减免。这一点对于申请硕士,希望拿到奖学金的学生来说是个好消息。
13、伍斯特理工学院
WPI 的 CS 有 37 个教授,大概方向有 6 个,分别是数据科学,生物信息与计算生物学,计算机安全,交互媒体和游戏开发,Learning Sciences & Technologies, 机器人工程。研究最热门的是人工智能、人机交互和网络/分布式系统。
MS 课程招生有两个方向,分别是computer/communications networks program 和 computer security。
申请特点
分数要求不算特别严格,特别是托福分数,目前看到我们有好几个案例都是托福分数不到 90 的;比较注重研究背景。这样的学校比较适合有一定的工作经验或者有比较丰富的项目经历,但是分数比较一般的学生去申请。
14、乔治华盛顿大学
GWU 的 CS 系比较小巧,主要从事 CS 专业下 8 个专业方向的研究:算法与理论、生物信息学与生物医学计算、计算机与信息安全、数字媒体、机器智能与认知、网络与移动计算、普适计算与嵌入式系统、软件工程与系统等。
其中,较有实力的方面是算法与理论以及生物信息学与生物医学计算。
申请特点
GWU 的 CS 系在招生方面录取门槛非常低,堪称又一个高综合排名 AD 狂。如果你的目标是申请综百前 50 的 CS,而分数不好,GWU 会是一个好的选择。从前几年的录取来看,GPA80 分左右,GRE310 分以上,TOEFL 90 分以上的申请者拿到录取的可能性非常高。
数据链路层2
复制自:https://www.cnblogs.com/zhangyinhua
阅读目录(Content)
一、局域网
1.1、局域网和以太网的区别和联系
局域网:前面已经介绍了,其实就是学校里面、各个大的公司里,自己组件的一个小型网络,这种就属于局域网。
以太网:以太网(Ethernet)指的是由Xerox公司创建并由Xerox、Intel和DEC公司联合开发的基带局域网规范,是当今现有局域网采用的最通用的通信协议标准。
以太网络使用CSMA/CD(载波监听多路访问及冲突检测)技术,并以10M/S的速率运行在多种类型的电缆上。
联系:是以太网就一定是局域网,但是局域网不一定就是以太网。 因为以太网就是一个规范,而大多数局域网都使用这个规范,所以才有这个话。
1.2、以太网常用的拓扑结构
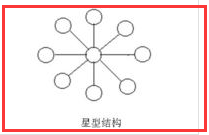
1)星状
这种结构的网络是各工作站以星形方式连接起来的,网中的每一个节点设备都以中防节为中心,通过连接线与中心 节点相连,如果一个工作站需要传输数据,它首先必须通过中心节点。
由于在这种结构的网络系统中,中心节点是控制中心,任意两个节点间的通信最多只需两步,所以,能够传输速度快,并且网络构形简单、建网容易、便于控制和管理。但这种网络系统,
网络可靠性低,网络共享能力差,并且一旦中心节点出现故障则导致全网瘫痪。
2)树形
树形结构网络是天然的分级结构,又被称为分级的集中式网络。其特点
是网络成本低,结构比较简单。在网络中,任意两个节点之间不产生回路,每个链路都支持双向传输,并且,网络中节点扩充方便、灵活,寻查链路路径比较简单。
但在这种结构网络系统中,除叶节点及其相连的链路外,任何一个工作站或链路产生故障会影响整个网络系统的正常运行。
3)总线型
总线形结构网络是将各个节点设备和一根总线相连。网络中所有的节点工作站都是通过总线进行信息传输的。
4)环形
环形结构是网络中各节点通过一条首尾相连的通信链路连接起来的一个闭合环形结构网。环形结构网络的结构也比较简单,系统中各工作站地位相等。
系统中通信设备和线路比较节省。在网中信息设有固定方向单向流动,两个工作站节点之间仅有一条通路,系统中无信道选择问题;某个结点的故障将导致物理瘫痪。
环网中,由于环路是封闭的,所以不便于扩充,系统响应延时长,且信息传输效率相对较低。
二、CSMA/CD协议(半双工通信)
局域网是用广播信道的方式去传送数据,那么就会遇到问题,如果在局域网内有两个pc机同时在其中传播数据呢?就会发生碰撞,使两个数据都失效,那么如何解决这个问题呢,使用CSMA/CD协议来解决这类问题。
2.1、概述
1)多址接入
一种多址接入协议,许多站点以多址接入的方式链接在一根总线上,其实就是局域网中总线网这种形式。
2)载波监听
发送前监听,就是在发送数据前监听总线中是否有数据在传播,如果有就不发送。就是用电子技术检测总线上有没有其他计算机发送的数据信号。
3)碰撞检测
边发送边监听,在发送数据的中途也会监听总线中是否会有其它数据,当几个站同时在总线上发送数据时,总线上的信号电压摆动值将会增大(互相叠加)。
当一个站检测到的信号电压摆动值超过一定的门限值时,就认为总线上至少有两个站同时在发送数据,表明产生了碰撞。 所谓“碰撞”就是发生了冲突。因此“碰撞检测”也称为“冲突检测”
检测到碰撞之后:
在发生碰撞时,总线上传输的信号产生了严重的失真,无法从中恢复出有用的信息来。
每一个正在发送数据的站,一旦发现总线上出现了碰撞,就要立即停止发送,免得继续浪费网络资源,然后等待一段随机时间后再次发送。
通过例子也说明一下CSMA/CD协议会做哪些事情,借用下面这个图来说明问题

分析:
第一步:B向D发送数据,在发送数据前,由于采用的CSMA/CD协议,那么先会进行载波监听,看总线中是否有其他的数据传输(如果检测,通过物理层的一些电磁波等)。
第二步:如果没有,那么B就可以开始发送数据,由于B到D之间存在一定距离,那么在总线中传输数据也要时间,虽然很快,可能只需要十几微秒,在发送的的途中,遇到C向A发送数据,
由于B到D的数据还没传过来,那么C也就没监听到总线中有数据,所以也开始发,那么在途中两个数据就会相遇,这就形成了碰撞,在碰撞以后,两个电磁波叠加,在总线中传输,
那么会到C或者B时,就会知道电磁波的不同,从而发生了碰撞。这就是碰撞检测。
2.2、详细描述
1)解释名词
传播延时:

争用期:发生碰撞所需要的最迟时间。在根据上面的大体分析,我们知道A到B之间的任意时刻都可能会发生碰撞,那么A确认发生碰撞要多久呢,那就是2t 了,传播时延是t,
可能正好到B那里就发生了碰撞,然后返回到A,又需要t的时间,那就是2t了,我们把这个2t时间就叫做争用期。
举例:在10Mb/s(传播速率)的以太网,争用期为51.2μs(微秒),那么在争用期内可发送64字节,及512bit的数据。怎么算来的呢?
10Mb/s = 10 000 Kb/s = 10 000 000 b/s (这里的换算是1000,指的是计算机网络中传输的多少位多少位,也就是0101这样的位数)
51.2μs = 0.0512 ms = 0.000 0512 s (1s = 1000ms = 1000 000 μs)
51.2μs能传多少bit呢? 上面两个相乘就为 512bit 了,换算为字节,字节的换算是 1byte(字节) = 8bit(位) 所以 512/8=64byte(字节) 就这样算过来的。
最短有效帧:64字节,就是上面这样算的,发送了64个字节之后,肯定就不会发生碰撞,以太网规定了最短有效帧长为 64 字节,凡长度小于 64 字节的帧都是由于冲突而异常中止的无效帧。
2)二进制指数类型退避算法
这个算法就是在发生碰撞后,pc机该如何处理,在什么时间后再次发送数据。
其实就是四部曲:
第一步:确定基本退避时间,一般就是争用期2t
第二步:定义参数k K = Min[重传次数,10]
第三步:从整数集合中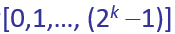 [0,1,…,(2的k次方 -1)]随机取一个数,记为r,重传所需要等待的时延就是r倍的基本退避时间(2rt)
[0,1,…,(2的k次方 -1)]随机取一个数,记为r,重传所需要等待的时延就是r倍的基本退避时间(2rt)
第四步:当重传16次还不能成功则丢弃该帧,并向高层汇报
解释:其实这四步很简单,我来分析一下就会了,首先第一次传数据,重传次数为0,那么k=0,从整数集合中只有0这个值,那么r=0,等待的时延就是2rt=0,所以第一次传数据需要等待的时延就是0,
不需要等待,除非先检测到了有数据已经在传了,如果第一传数据发现碰撞,那么重传次数为1,那么k=1,整数集合中就有0,1两个值,随机取值,取到r=1,那么等待的时延就是2t,意思就是
在第一次发生碰撞后,需要等待2t的时间,才能在重新发送数据,也可能不需要等就直接发,r=0时。
二、以太网信道利用率问题
分析图:

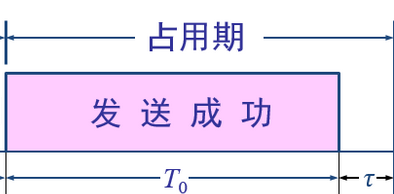
分析:一个帧从开始发送,经可能发生的碰撞后,将再重传数次,到发送成功(发送成功这段时间T0是指数据的发送时延,帧长为 L (bit),数据发送速率为 C (b/s),因而帧的发送时间为 L/C = T0 (s)),
帧发出去以后,还要经过端到端的传播时延t,所有在真正占用信道的时间是 TO+t ,前面发生的碰撞损耗的时间,数据并没有占用信道,我们指真正占用信道的时间是指数据发送成功即不发生
碰撞然后到达目的地的这段时间,而前面发生碰撞的时间,都市在浪费信道,每发送一帧需要的平均时间就是在信道中发生碰撞浪费的时间+上数据传输成功所用的占用期。不要理解错了。
公式和参数a的理解: 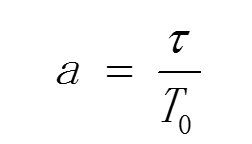 首先理解一下信道利用率,借用上面的图,就是占用期在其图中的比例变大,则信道利用率就高。但是不确定前面发生了多少次碰撞,
首先理解一下信道利用率,借用上面的图,就是占用期在其图中的比例变大,则信道利用率就高。但是不确定前面发生了多少次碰撞,
只是一个平均的估算值,所以就定义了这个a的公式,用t/T0来代表信道利用率
1)a→0 表示一发生碰撞就立即可以检测出来,并立即停止发送,因而信道利用率很高。
a→0也就是t越小,而T0越大,发送时延尽可能大一点,而t传播时延尽可能小一点,现实意义就是数据在在信道中传播的时间如果很小很小,那么数据一发送,
就能在很少的时间里面检测出碰撞来了,那么在前面那张图中,花费在争用期(发生碰撞)的时间就少了,就能快点成功发送数据占的时间就长了了,那信道的利用率不就很高吗,
2)a 越大,表明争用期所占的比例增大,每发生一次碰撞就浪费许多信道资源,使得信道利用率明显降低
就是T0越小,而r很大,那发生一次碰撞就浪费了很多信道资源,因为在信道中传输无用的波占的时间太长了。而成功发送的占用期自然就变小了,所以信道利用率就越低了。
根据上面的分析信道利用率,就发现,影响信道利用率的就跟T0和t有关,也就是跟以太网的连线长度有关,所以才有在以太网中,有最远距离的限制,就是不能让t太大,
以至于a很大,信道利用率太低,还有发送的帧长也有最小帧长的限制,因为怕发送的数据帧太短,而发送速率就一定,那么发送时延T0就太小了,会让a的值越大,信道利用率就太低了。
2.1、最大信道利用率
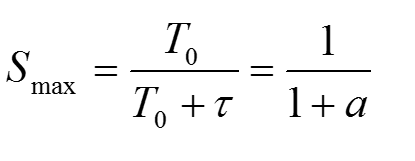
理想的情况下就是不发生碰撞,一发送完数据,另一个数据就又发送,也就是一有空闲时间,就发送数据。这个时候,信道中一直有数据在传输,一刻也不停歇,那此时的信道利用率就是100了?
错误,这个想法是错的,举个例子就知道了。每帧用的时间就是下面图中这块,这块也就可以看成一段数据帧平均花费的时间,这里面所影响的因素就是发送时延T0和t传播时延了,一段数据帧平均花费的时间为1s,
这是已经固定了,但是其中的两个部分并没有确定,如果T0占的比例大,说明发送时延大,发送速率已经确定了,那么就肯定是发送的数据变多了,在信道中传输的bit更过,信道利用率不就更到了吗,通俗一点讲,
就是给了你1s的时间,你尽可能的多发些bit过去,那么你的传播时延就大了,那不就信道利用率的很高了吗,理想状态下考虑的因素跟那个现实考虑的因素不一样。
对CSMA/CD协议的讨论,大概就是这些内容了,刚才讨论的前提是已经知道谁发送给谁了,然后说的数据在传播过程中遇到的问题。
三、PC机与PC机怎么找到对方
用的就是MAC地址,在以太网中是如果封装数据帧来达到能够准确传输数据到目的地的呢?
MAC地址的格式:
48bit,6个字节,前3个字节是由管理机构给各个厂家分配的。也就是说如果有厂家想生产网卡这类需要mac地址的东西,必须先像管理机构申请前三位字节,
所以网卡上的前三个字节就代表着某个厂家,后三个字节就是由厂家自己来设定的。
每个网卡都拥有识别数据帧中mac地址的功能
数据帧格式:
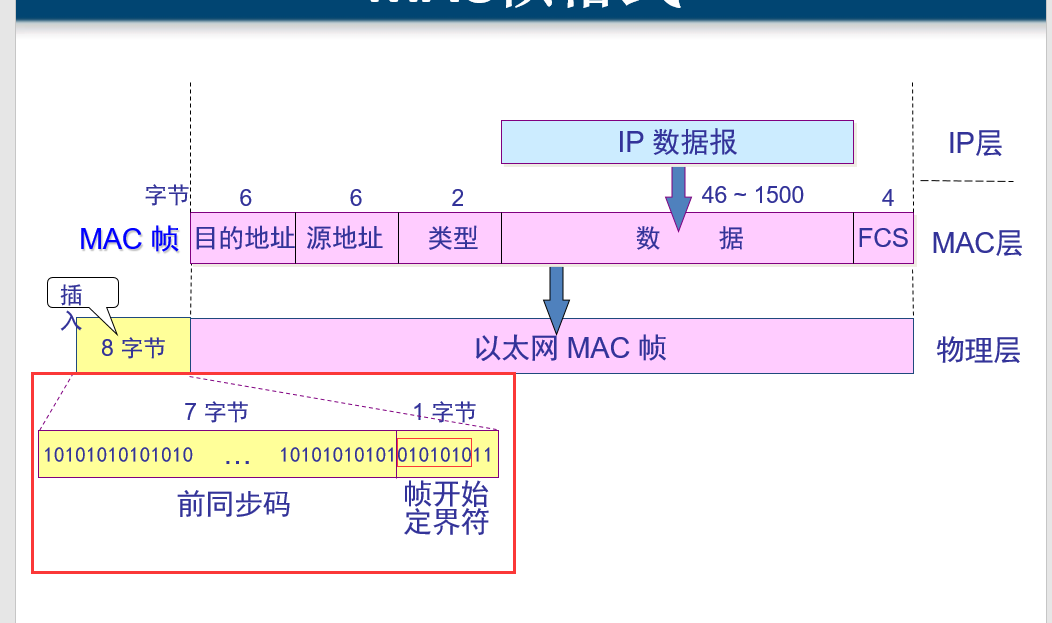
先不管前8个插入字节的意思,在以太网中,发送的数据帧最小要是64个字节,那这64个字节由哪些组成的呢,就是图中所示,6个目的MAC地址,6个源MAC地址,2个字节代表数据包的类型,
还有4个字节是FCS,用来进行CRC算法检测的,剩下的46个字节就是数据包最少要发送的字节数了,如果数据包实际发的少于46,那么会给这个数据包自动补充0,来达到需要的字节数。
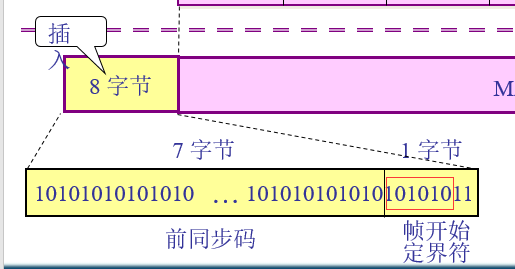
然后说说插入的8个字节是什么意思?前7个字节用来使发送的数据帧的的比特同步,也叫作前同步码,最后一个字节,帧的开始定界符,也就是告诉接收方,从这个字节开始,后面是是MAC帧了。
有人这个时候会问,既然有了帧开始定界符,为什么还要同步码?原因是,在接受MAC帧后,并不能马上识别出帧开始定界符,没有那么快的反应分辨出来,所以需要在前面加同步码,使接收方有反应的时间,
所以同步码都是1010101010101这样的bit。前7个字节的同步码跟最后一个字节中的前6个bit位相同。上面图中这里画的有点错误,圈错了,正确的是下面这样:
三、扩展以太网
集线器和网桥(多个接口的交换机)
3.1、集线器
1)概述
集线器(HUB)属于数据通信系统中的基础设备,它和双绞线等传输介质一样,是一种不需任何软件支持或只需很少管理软件管理的硬件设备。它被广泛应用到各种场合。集线器工作在局域网(LAN)环境,
应用于OSI参考模型第一层,因此又被称为物理层设备。集线器内部采用了电器互联,当维护LAN的环境是逻辑总线或环型结构时,完全可以用集线器建立一个物理上的星型或树型网络结构。在这方面,集线器
所起的作用相当于多端口的中继器。其实,集线器实际上就是中继器的一种,其区别仅在于集线器能够提供更多的端口服务,所以集线器又叫多口中继器。HUB按照对输入信号的处理方式上,可以分为无源HUB、有源HUB、智能HUB。
2)工作过程
集线器的工作过程是非常简单的,它可以这样的简单描述:首先是节点发信号到线路,集线器接收该信号,因信号在电缆传输中有衰减,集线器接收信号后将衰减的信号整形放大,最后集线器将放大的信号广播转发给其他所有端口。
就是只能够转发数据,来了就往接了集线器的PC机上发数据,其他什么差错校验呀,什么东西全都不做,
集线器的用法首先是下面这样

然后想办法,改进成这样了
改完是有好处也有坏处
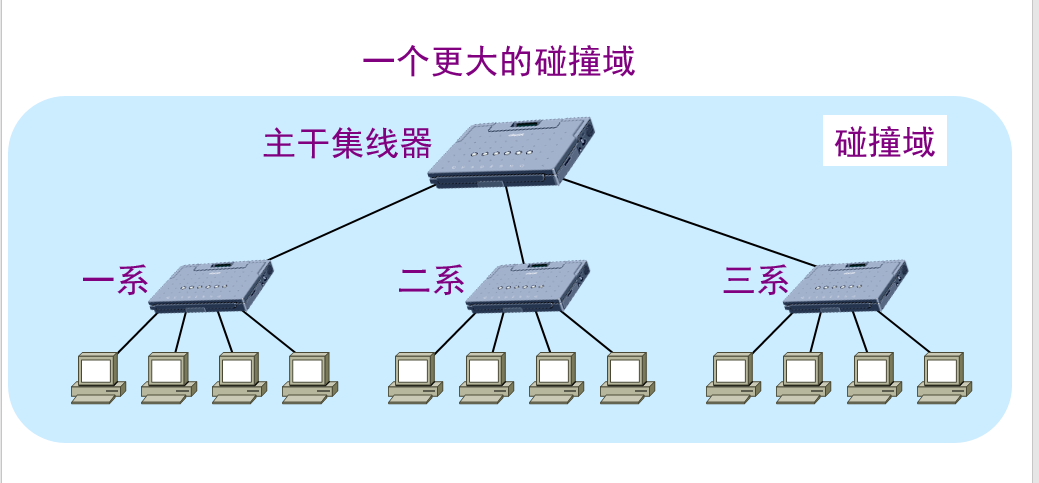
用集线器扩展局域网优点:
使原来属于不同碰撞域的局域网上的计算机能够进行跨碰撞域的通信。
扩大了局域网覆盖的地理范围。
用集线器扩展局域网缺点:
碰撞域增大了,但总的吞吐量并未提高。
如果不同的碰撞域使用不同的数据率,那么就不能用集线器将它们互连起来。
由于集线器总有这样的缺点,所以网桥这个设备就出来了
3.2、网桥
1)概述
也有人把“网桥”比喻成一个聪明的中继器(Repeater)。因为中继器只是对所接收的信号进行放大,然后直接发送到另一个端口连接的电缆上,主要用于扩展网络的物理连接范围;
而网桥除了可以扩展网络的物理连接范围外,还可以对MAC 地址进行分区,隔离不同物理网段之间的碰撞(也就是隔离“冲突域”)。集线器和中继器都是物理层设备,而网桥属于二层设备。
我们经常听到这样的说法,那就是“网桥”是一种可连接不同网段的二层网络设备(二层交换机也一样),一个端口可以连接一个网段。所以很多人总在纳闷,网桥怎么能连接不同网段呢?
其实这是因为大家对这里所说的“网段”并不理解。其实这里“网段”更准确地讲应该是叫“物理网段”,是指IP 地址属于同一网络地址段(也就是IP 地址中的网络ID一样),位于不同地理位置的不同LAN 分段,
是基于物理意义上的地理区域进行划分的。我们常说的网段是指IP 地址属于不同网络地址段的网络或子网,是一个三层概念,其实这应该叫做逻辑网段,是基于逻辑意义上的网络地址进行划分的。
(hzhsan:就是说这里的网段是物理网段,并不是我们平时说的IP网段,不关心三层上的概念)
无论是网桥,还是二层交换机,虽然每个端口可以连接一个网段,但是它们所连接的主机都在同一网络,或者同一子网中。如连接的主机位于不同办公室或者不同办公楼中,则可采用同一网络地址的两个或多个小LAN,
以组成一个可以统一管理的大LAN。但要注意的是,因为网桥只有两个端口,所以所连接的两个物理网段的主机通常就是由当时的集线器进行集中连接的(网桥端口通常不是直接连接主机的)。
软件中通常所说的桥接(如VMware中的桥接工作模式)也就是网桥的作用,它连接的也是同一网络或子网中的两个网段。
网桥都是只有两个端口吗?应该可以有多个端口吧?
答案:基本网桥只有两个端口,还有一种网桥叫做多口网桥,多口网桥有多个端口
 图1
图1
2)优点
有两个优点,能识别mac地址,遇到陌生的mac地址,会在内部mac表中记录下该mac地址,下次再使用,就认识了
1.1)根据 MAC 帧的目的地址对收到的帧进行转发
2.2)过滤帧的功能。当网桥收到一个帧时,并不是向所有的接口转发此帧,而是先检查此帧的目的 MAC 地址,然后再确定将该帧转发到哪一个接口
3)网桥原理
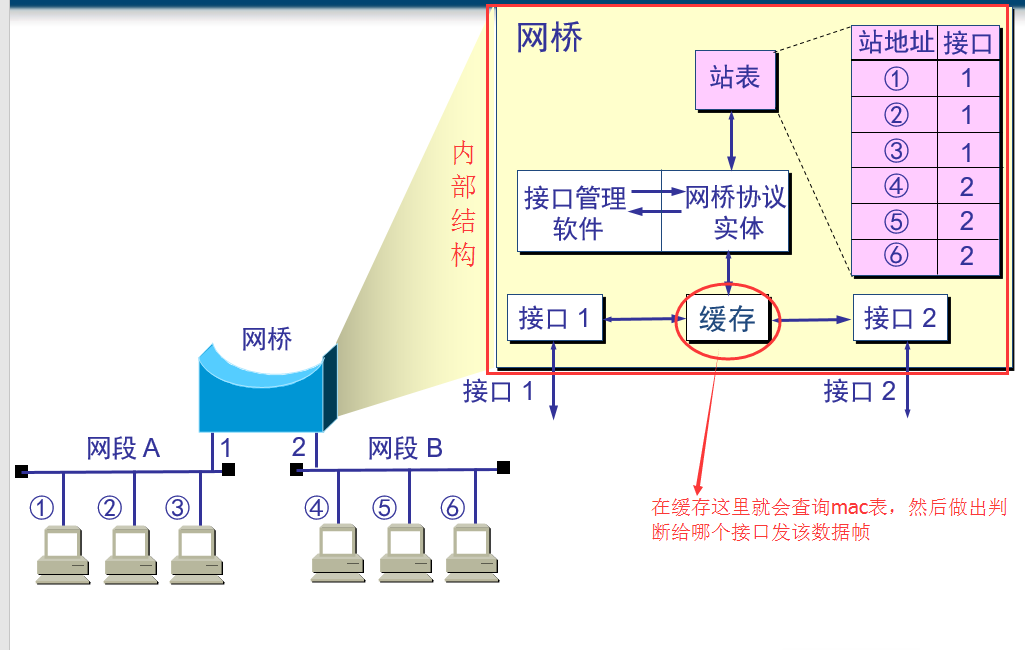 )
) 图2
图2
前面说到了网桥具有两种主要特性:一是可基于物理网段的MAC 地址进行学习,二是可以隔离冲突域。下面通过一个示例来进行解析。
假设图1 中所示的物理网段1 和物理网段2 中的主机都是通过集线器集中连接的,则这样这两个物理网段各自形成一个冲突域,因为集线器是采用共享介质传输的,
而网桥的背板信道不是共享的(每个端口的数据收发都有一条单独的信道),所以一个集线器就是一个冲突域。网桥的数据转发原理如图2所示。下面是具体的解析。
说明 MAC 地址表也就是通常所说的CAM(Content Addressable Memory,内容可寻址存储器)表,保存的是对应MAC 地址主机与所连接的交换机端口的映射。这个映射表项可以由管理员手动绑定创建,
也可以由交换机自动学习得到。在交换机上可以通过一些命令(如Cisco 交换机是使用show mac-address-table 命令)查看。下面是一个在交换机上查看MAC 地址和端口映射表的示例,其中列出了交换机中
为CPU 分配的静态(static)MAC 地址和通过学习功能自动学习得到的动态(dynamic)MAC 地址,其中的Ports 列显示的是对应MAC 地址主机所连接的端口,VLAN 列则为对应主机连接端口所属的VLAN。
 mac-address-table
mac-address-table
现假设图5-34 所示网络中的一台PC 要向另一台PC 发送数据。因为集线器也是物理层设备,不能识别帧中的MAC 地址,所以无论是哪台主机要发送数据,在集线器上都是以广播方式进行的,
连接该集线器上的所有节点都会收到这个广播帧,包括网桥连接到该集线器的端口。
1)当网桥收到集线器的广播帧后,网桥会把帧中的源MAC 地址和目的MAC 地址与网桥缓存中保存的MAC 地址表进行比较。
2)最初,网桥的缓存中是没有任何MAC 地址的,所以一开始它也不知道哪台主机在哪个物理网段上,收到的所有帧都直接以泛洪方式(也是复制原数据帧)转发到另一个端口上,
同时会把数据帧中的源MAC 地址所对应的物理网段记录下来(其实就是与对应的网桥端口对应起来)。
3)在数据帧被某个PC 机接收后,也会把对应目的MAC 地址所对应的物理网段记录在缓存中的MAC 表中。这样,经过多次这样的记录,就可以在MAC 地址表中把整个网络中各
主机MAC 地址与对应的物理网段全部记录下来。因为网桥的端口通常是连接集线器的,所以一个网桥端口会与多个主机MAC 地址进行映射。
4)当网桥收到的数据帧中源MAC 地址和目的MAC 地址都在网桥MAC 地址表中可以找到时,网桥会比较这两个MAC 地址是否属于同一个物理网段。如果是同一物理网段,
则网桥不会把该帧转发到下一个端口,直接丢弃,起到冲突域隔离作用。相反,如果两个MAC 地址不在同一物理网段,则网桥会把从一个物理网段发来的帧转发到连接
另一个物理网段上,然后再通过所连接的集线器进行复制方式的广播。
3)透明网桥
局域网上的站点并不知道所发送的帧将经过哪几个网桥,因为网桥对各站来说是看不见的
是一种即插即用设备,其标准是 IEEE 802.1D
4)网桥的优点与缺点
优点:
过滤通信量。
扩大了物理范围。
提高了可靠性。
可互连不同物理层、不同 MAC 子层和不同速率(如10 Mb/s 和 100 Mb/s 以太网)的局域网。
缺点:
存储转发增加了时延。
在MAC 子层并没有流量控制功能。
具有不同 MAC 子层的网段桥接在一起时时延更大。
网桥只适合于用户数不太多(不超过几百个)和通信量不太大的局域网,否则有时还会因传播过多的广播信息而产生网络拥塞。这就是所谓的广播风暴。
四、高速以太网
从最早的使用集线器连接的以太网(CSMA/CD,半双工,10Mb/s)到使用网桥阶段的扩展以太网(CSMA/CD,半双工,10Mb/s或100Mb/s)到现在的高速以太网(半双工/全双工通信)。
4.1、高速以太网
速率达到或超过100Mb/s的以太网
这个也没什么好讲的,就是在之前的基础上加强了很多东西,
速率提高了很多
从半双工通信到能使用全双工通信了(这个并不是说就抛弃了半双工,在星形拓扑结构中的局域网,也就使用CSMA/CD协议的半双工通信的方式,全双工就不使用该协议了)
传输距离可以增长,因为有了光纤(传输过程的稳定性),速率增强很大,不止局限于局域网,扩展到了有城域网,广域网。
4.2、10Gb/s以太网
1)概述
与 10 Mb/s,100 Mb/s 和 1 Gb/s 以太网的帧格式完全相同。
保留了 802.3 标准规定的以太网最小和最大帧长,便于升级。也就是最小64字节,最大是多少不知道。
不再使用铜线而只使用光纤作为传输媒体。
只工作在全双工方式,因此没有争用问题,也不使用 CSMA/CD 协议。
2)优点
成熟的技术
互操作性很好
在广域网中使用以太网时价格便宜。
统一的帧格式简化了操作和管理